

近日,人工智能领域国际顶级学术会议AAAI 2026公布录用结果。我校音乐人工智能与音乐信息科技系博士生童心怡、陈吉尚等的论文《Video Echoed in Music: Semantic, Temporal, and Rhythmic Alignment for Video-to-Music Generation》从全球23,680篇高水平投稿中脱颖而出,被Main Technical Track接收,并获得了Oral Presentation(大会口头报告)的殊荣。AAAI(Association for the Advancement of Artificial Intelligence)是国际人工智能领域历史最悠久、影响力最广泛的顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际会议。作为全球人工智能研究的“风向标”,AAAI一直以录用标准严格著称。中稿论文能够获得会议Oral Presentation难度极高,仅有在原创性、学术影响力、技术突破性与行业引领性等方面达到国际前沿的成果才能入选。AAAI 2026将于1月20-27日在新加坡举行,届时将成为全球AI学者交流与合作的重要平台。这一成果标志着我校在音乐人工智能领域的创新研究再获得国际学术界的高度认可,并在技术与学术影响力上迈入全球领先行列。

论文首页
1、论文简介
自动为视频生成契合的背景音乐(Video-to-Music, V2M)是多媒体内容创作与人工智能交叉领域的重要研究方向。优质视频配乐不仅能显著增强视频的情感表达与叙事张力,还能提升沉浸体验,在影视制作、游戏开发、广告营销、短视频创作等领域具有广阔应用前景与商业价值。当前视频配乐生成技术仍面临两个长期存在的核心瓶颈,制约着其实际应用效果。
一方面,现有方法对视频信息的表征能力不足。当前主流方法,无论是基于预设规则或视觉特征的生成范式,还是将视频内容转换为文本描述后再进行音乐生成的路径,均难以全面、精准地捕捉视频所蕴含的丰富视觉语义信息及其内在的精细时间结构。这种表征能力的局限性直接导致了生成音乐与视频内容在语义层面的对齐效果欠佳,两者间的深层关联性未能得到充分体现。
另一方面,时间与节奏对应关系的精度缺失。实现视频中关键事件(如场景切换、动作变化)与音乐核心元素(如节拍、重音)之间的高精度同步,对于构建流畅、富有感染力的沉浸式视听融合体验至关重要。然而,现有模型在处理此类时间同步任务时,大多仅能在局部片段或粗粒度时间尺度上实现有限的匹配,难以达到帧级精度的精准一致。这种“转场-节拍”对齐能力的不足,严重制约了生成音乐在时间维度上与视频动态变化的契合度。
为了解决上述难题,中央音乐学院、北京通用人工智能研究院与阿里巴巴集团联合团队提出了视频配乐生成框架VeM(Video Echoed in Music)。该框架首次将多层级视频解析结果作为音乐生成的“指挥”,在潜空间扩散模型中融合全局语义、分镜级时间信息及帧级场景转场,通过分镜引导跨注意力机制(SG-CAtt)精确实现语义与时间双对齐,并结合转场-节拍对齐器与适配器(TB-As)在帧级实现场景切换与节拍事件的精准同步,从而同时满足视频配乐的情绪契合度与节奏精度。在模型训练过程中,团队构建了专为转场-节拍同步设计的高质量视频音乐数据集TB-Match,并引入了适配该任务的全新节奏对齐评测指标,使生成与评价环节在时间与节奏特性上形成闭环优化。
实验结果表明,VeM在音乐质量、语义匹配、时序同步和节奏精度四个维度均显著超越现有方法,特别是在保持音乐风格一致性的同时,实现了转场与节拍的高保真对齐,为电影、广告、游戏、短视频等领域提供了能够自动生成高质量、精准对齐背景音乐的解决方案,并为多模态对齐和可编辑音乐生成开辟了新的研究路径。
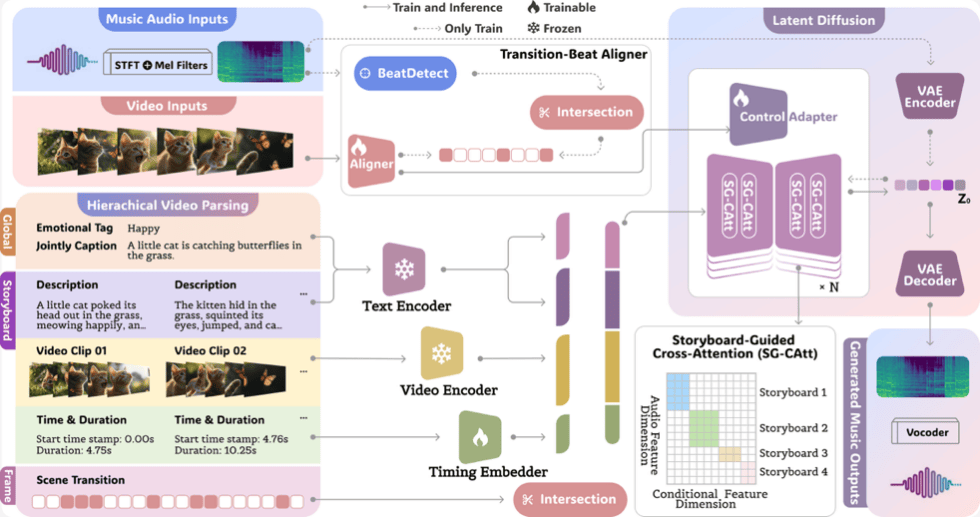
基于潜空间音乐扩散模型(Latent Music Diffusion)来同时实现视频与音乐在语义、时间以及节奏三个维度上的精确对齐
该工作在方法层面,首次将视频解析的全局、局部和帧级信息系统化地引入音乐生成扩散模型,使V2M任务在语义、时间和节奏三个关键维度上达到全面、精确的对齐,解决了现有方法只关注部分细节、缺乏精细同步的短板;在应用层面,能够自动生成既与视频语义契合,又能在时间和节奏上精准匹配的高质量配乐,为影视后期、广告制作、游戏开发、短视频创作等场景提供高效、低成本且版权安全的解决方案;在数据与评测贡献方面,TB-Match数据集及其严格的转场-节拍注释为该领域研究奠定了坚实基础,新的节奏对齐评测指标也为后续方法的客观评价提供了标准。更重要的是,VeM具备跨域泛化能力,在不同类型视频中均能保持高水准的表现,这为未来进一步研究可编辑的音乐生成以及更复杂的多模态对齐技术开辟了新的方向。
2、成果展示
实验结果显示VeM在客观和主观评价中均显著优于五个先进基线模型。在九项客观指标上,VeM 均取得最佳表现。主观评价中,包含影视音乐专家与普通观众在内的50位参与者在Top-1偏好率、音乐质量评分以及视频音乐契合度评分方面均显著偏向VeM。进一步的跨域泛化实验表明,在SymMV、Sora生成视频以及随机视频数据上,VeM依然保持领先,体现出良好的零样本泛化能力。
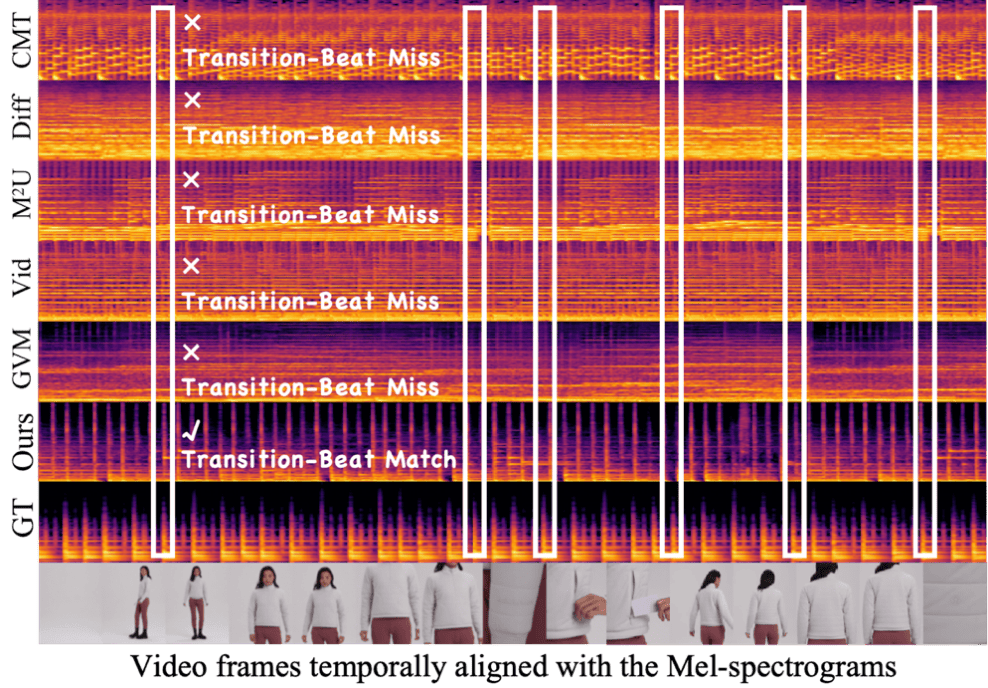
相较于对比方法,VeM在生成配乐与视频节奏的
卡点上有着更好表现
生成视频配乐样例:
)
)
)
)
)
)
(高潮丸有没有副作用))
)

)
)
)
)
)
)
)