
henry 发自 凹非寺
量子位 | 公众号 QbitAI
要说真学术,还得看推特。
刚刚,谢赛宁自曝团队新作iREPA其实来自4个多月前的,一次与网友的辩论。

这场短暂的线上辩论虽然以谢赛宁被网友说服告终,但在3个多月后,居然有了意料之外的后续——
多个团队合作,沿着这一思路写出了一篇完整的论文,而且核心框架仅需3行代码。

致谢部分还感谢了当时参与讨论的网友。
一篇推特引发的学术论文
事情是这样的。
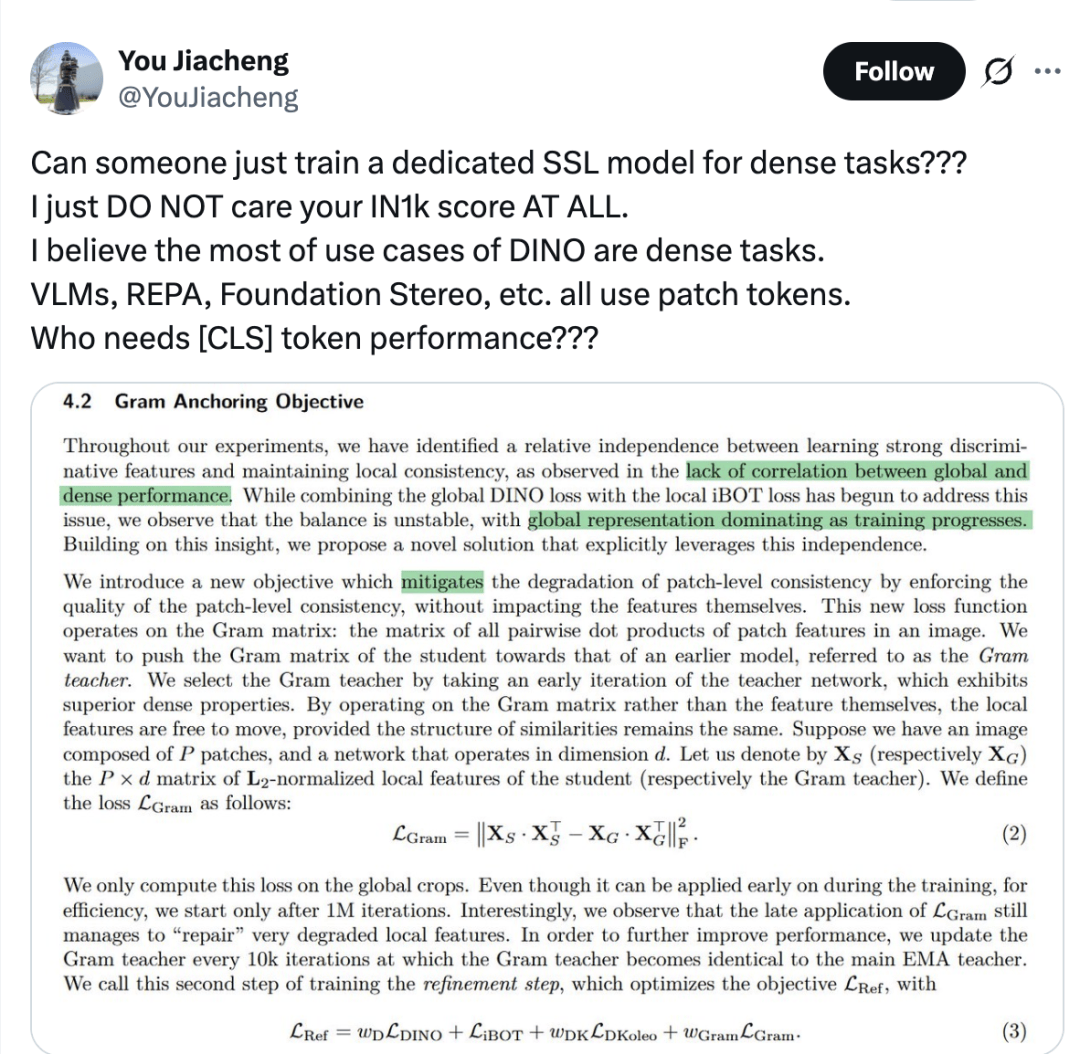
展开全文一位网友在8月份表示:
别再痴迷于ImageNet-1K的分类分数了!自监督学习(SSL)模型应该专门为稠密任务(如REPA、VLM等)进行训练,因为这些任务真正依赖的是patch tokens中的空间和局部信息,而不是[CLS]token所代表的全局分类性能。
别再痴迷于ImageNet-1K的分类分数了!自监督学习(SSL)模型应该专门为稠密任务(如REPA、VLM等)进行训练,因为这些任务真正依赖的是patch tokens中的空间和局部信息,而不是[CLS]token所代表的全局分类性能。
(注:稠密任务就是要求模型对图像中的“每一个像素”或“每一个局部区域”都做出预测的计算机视觉任务,这类任务需要精确的空间和局部细节信息,而不仅仅是全局分类标签)
对于网友的观点,谢赛宁表示:
不,使用patch token并不意味着就是在做稠密任务。VLM和REPA的性能与它们在IN1K上的得分高度相关,而与patch级别的对应关系只有很弱的关联。这并不是[CLS]token的问题,而是高层语义与低层像素相似性之间的差别。
不,使用patch token并不意味着就是在做稠密任务。VLM和REPA的性能与它们在IN1K上的得分高度相关,而与patch级别的对应关系只有很弱的关联。这并不是[CLS]token的问题,而是高层语义与低层像素相似性之间的差别。
对于谢赛宁的反驳,网友举出了SigLIPv2和PE-core优于DINOv2 for REPA的例子。

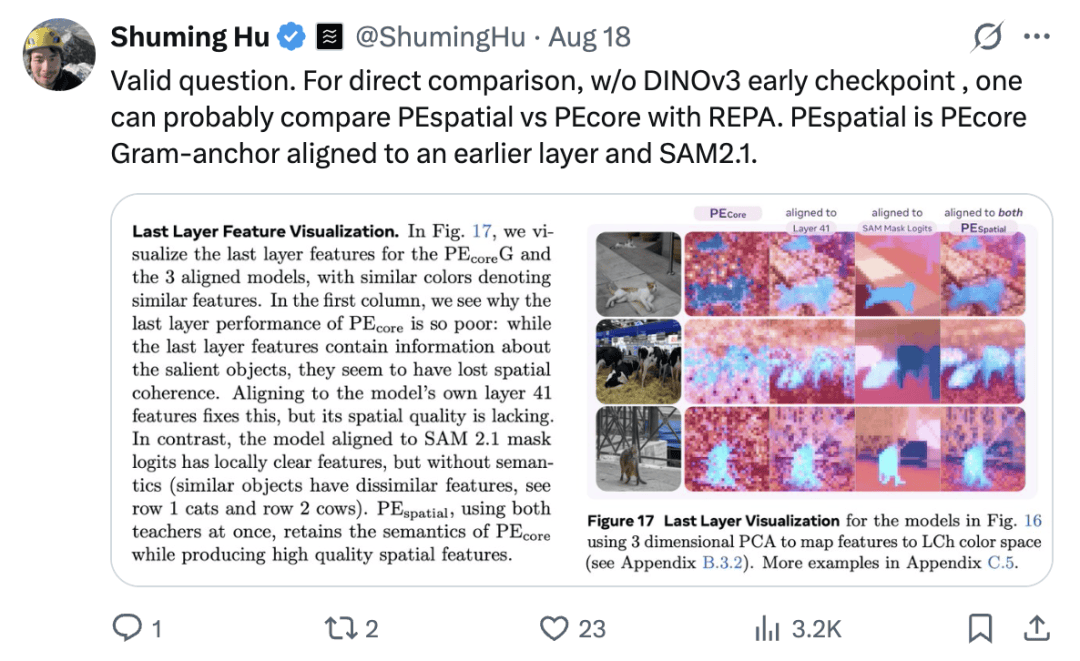
与此同时,另一位网友也加入了战斗:
这是个合理的问题。为了做直接对比,在没有DINOv3早期checkpoint的情况下,或许可以用REPA来比较PEspatial和PEcore。其中,PEspatial可以理解为:将PEcore的Gram-anchor对齐到更早的网络层,并结合SAM2.1。
这是个合理的问题。为了做直接对比,在没有DINOv3早期checkpoint的情况下,或许可以用REPA来比较PEspatial和PEcore。其中,PEspatial可以理解为:将PEcore的Gram-anchor对齐到更早的网络层,并结合SAM2.1。
对此,谢赛宁表示:
非常好!感谢你的指路/提示。我很喜欢这个方案。否则干扰因素会太多了。两个checkpoint都已经有了(G/14,448 分辨率),希望我们很快就能拿到一些结果。
非常好!感谢你的指路/提示。我很喜欢这个方案。否则干扰因素会太多了。两个checkpoint都已经有了(G/14,448 分辨率),希望我们很快就能拿到一些结果。
3个多月后,谢赛宁表示自己之前的判断站不住脚,而且这次的论文反而带来了更深入的理解。
还有贴心小贴士,提示网友可以看看致谢部分。
对于自己在致谢中被提到,参与讨论的网友之一表示很有意思:
也谢谢你一路跟进!被致谢提到我也很受宠若惊。
也谢谢你一路跟进!被致谢提到我也很受宠若惊。
谢赛宁还表示,这次讨论本身就是一次小实验——他想看看,一种新的“线上茶水间效应”是否真的能够发生。
他很享受这种状态:先有分歧、有争论,再通过真正的实验和投入,把直觉拉回到可被验证的科学结论上。
不得不说,这样开放、即时、可纠错的学术讨论,确实值得多来一些。
接下来,我们就一起来看看由此催生的最新论文。
空间结构才是驱动目标表征生成性能的主要因素
承接上面的讨论,这篇最新论文探讨了一个核心的基础问题:
在用预训练视觉编码器表征来指导生成模型时,究竟是表征的哪一部分在决定生成质量?
是其全局语义信息(ImageNet-1K上的分类准确率)还是其空间结构(即补丁tokens之间的成对余弦相似度)?
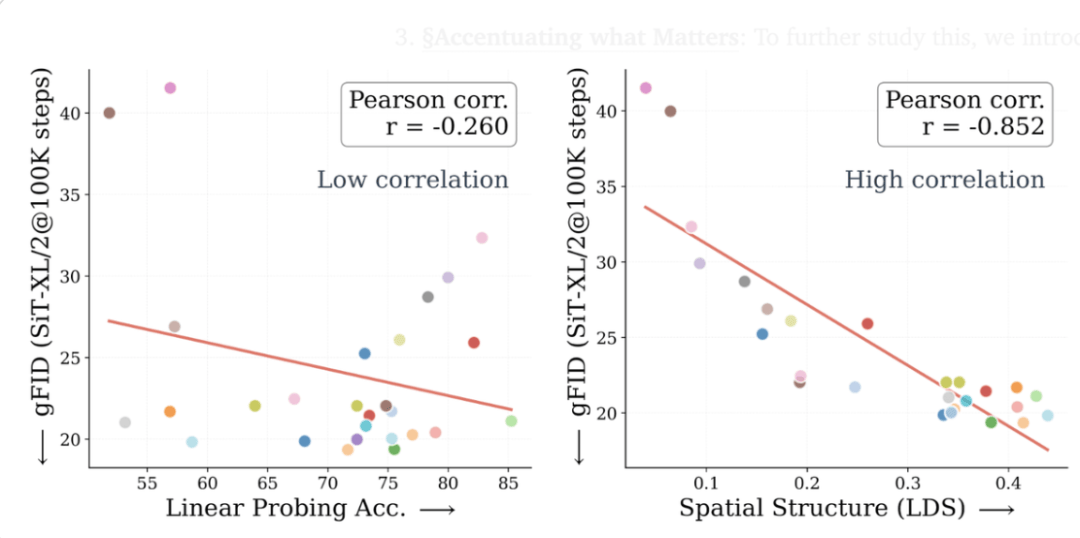
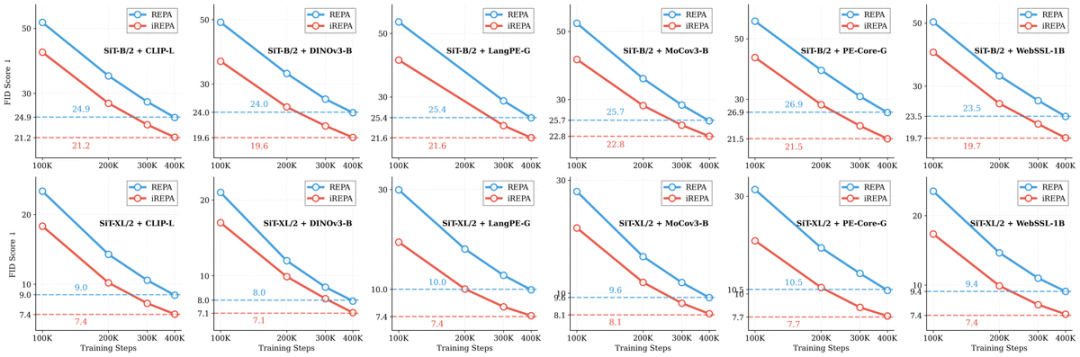
论文给出的结论是:更好的全局语义信息并不等于更好的生成,空间结构(而非全局语义)才是表征生成性能的驱动力。
传统观念(包括谢赛宁本人)认为具有更强全局语义性能的表征会带来更好的生成效果,但研究却表明更大的视觉编码器反而可能带来更差的生成性能。
其中,线性检测准确率只有约20%的视觉编码器,反而可以超过准确率>80%的编码器。
而且,如果试图通过CLS token向patch token注入更多全局语义,生成性能还会被拉低。
与此同时,研究还发现生成效果更好的表征,往往具有更强的空间结构(可通过空间自相似性指标来衡量):
也就是说,图像中某一部分的token会如何关注图像中其他区域的token。
在具体的研究方法上,研究通过一次大规模的定量相关性分析对这一观察进行了细化验证:分析覆盖了27 种不同的视觉编码器(包括 DINOv2、v3、Perceptual Encoders、WebSSL、SigLIP 等)以及 3种模型规模(B、L、XL)。
而在进一步的评测中,空间信息的重要性被进一步拔高:即便是像SIFT、HOG这样的经典空间特征,也能带来与PE-G等现代、更大规模视觉编码器相当、具有竞争力的提升。

在测试得出结论后,论文又基于现有的表征对齐(REPA)框架进行分析和修改,提出了iREPA。
投影层改进: 将REPA中标准的MLP投影层替换为一个简单的卷积层。
空间规范化: 为外部表征引入一个空间规范化层。
投影层改进: 将REPA中标准的MLP投影层替换为一个简单的卷积层。
空间规范化: 为外部表征引入一个空间规范化层。
这些简单的修改(如在DeCo框架下的实现)旨在保留并强化空间结构信息,相比原始的REPA方法能显著提升性能。
值得一提的是iREPA,只需3行代码即可添加到任何表示对齐方法中,并且在各种训练方案(如REPA、REPA-E、Meanflow 以及最近推出的 JiT)中都能实现持续更快的收敛。
参考链接
[2]https://arxiv.org/abs/2512.10794
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)