
12 月 10 日,智谱 AI 正式开源最新多模态大模型 GLM-4.6V,其在图像理解、图表解析、细粒度视觉描述等领域的表现全面超越 GPT-4V、Qwen-VL 等主流模型,为基于文档的智能问答、分析生成提供了更强大的技术支撑。
多模态大模型在处理含复杂表格、手写批注、多元素融合的文档时,长期存在因信息提取不精准、语义理解不充分而产生 “幻觉”—— 输出与文档实际信息脱节的虚构内容的问题,这也是众多大模型持续优化升级的方向。这一问题削弱了大模型的应用价值,更可能给工作带来潜在风险。
如何从源头解决文档理解环节的信息偏差,让大模型的强大能力充分落地?合合信息的 TextIn 文档解析工具给出了针对性解决方案。
大模型“幻觉”的隐患
大模型基于文档回答时的 “幻觉” 问题,已成为制约工作效率与结果可靠性的核心痛点,其难点与连锁影响集中体现在三方面:
● 文档理解存在天然局限:多模态模型虽具备图像识别能力,但面对复杂表格(如合并单元格、跨页表、框线残缺表)、手写批注、印章覆盖的文档,或融合文本、图表、公式、签名的多元素综合体时,难以精准提取关键信息,无法完成基础的 “信息读懂” 环节,只能通过 “脑补” 填补信息空白,导致幻觉产生。
● 效率提升预期落空:当用户借助大模型生成行业报告分析、论文数据解读等建议性内容时,若输出包含大量 “胡言乱语” 式的虚构信息,需额外增加校对环节,逐一核对原文与输出结果的一致性,不仅未节省时间,反而增加了工作流程,违背了效率提升的初衷。
● 潜在风险隐患突出:在合规审核、数据核对等严肃场景中,人工校对的疏漏可能导致错误信息流入后续工作,引发合规风险或决策偏差,而幻觉带来的信息失真,正是这类风险的核心源头。
TextIn 文档解析,让文档成为大模型可读懂的语言
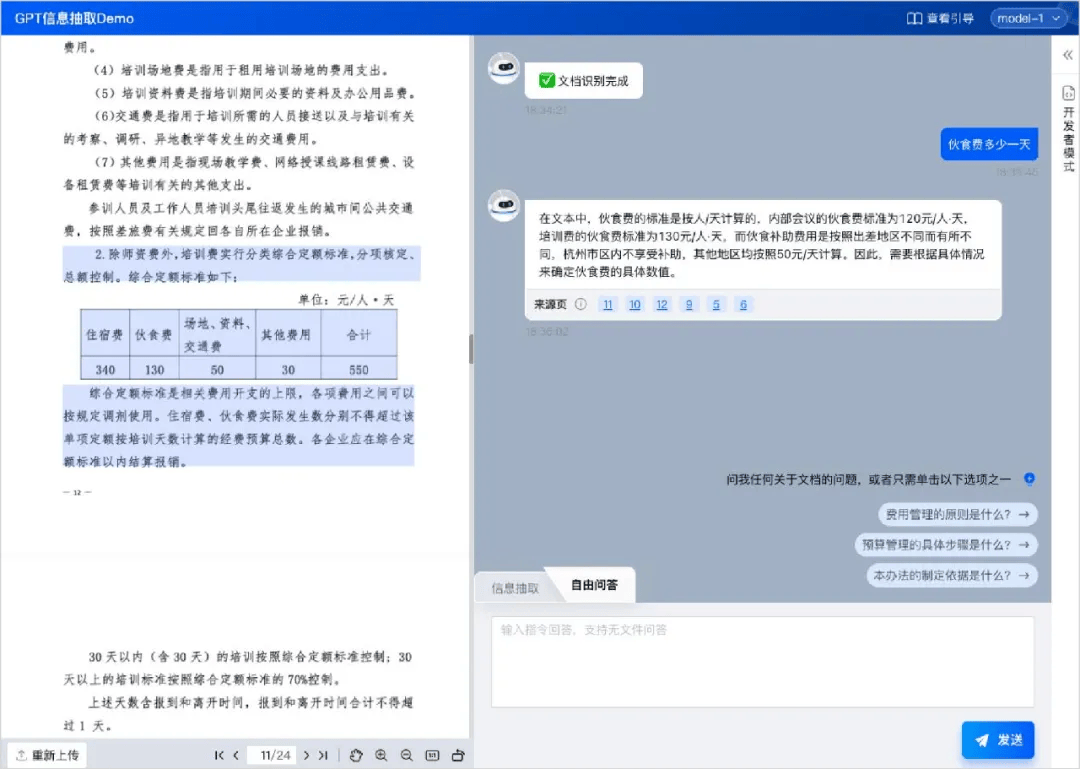
TextIn 文档解析工具聚焦大模型 “读不懂文档” 的源头矛盾,以 “精准解析 + 结构化输出” 为核心,为大模型提供高质量输入数据,从根本上减少幻觉产生。其核心定位是 “大模型加速器”,通过先进的深度学习技术,将非结构化文档按逻辑与元素分离识别,精准提取文本、表格、图表、公式、手写体、印章等各类信息,并转化为模型可直接理解的结构化格式,让大模型能 “清晰读懂” 文档细节,避免 “脑补式” 回答。
该工具支持 PDF、Word、Excel、图片、手写笔记等多种文档格式,可适配行业报告、学术论文、合规文件、业务单据等各类应用场景,既适用于个人高效办公,也能满足企业级文档处理的严苛需求,与主流多模态大模型形成完美协同。

操作步骤讲解
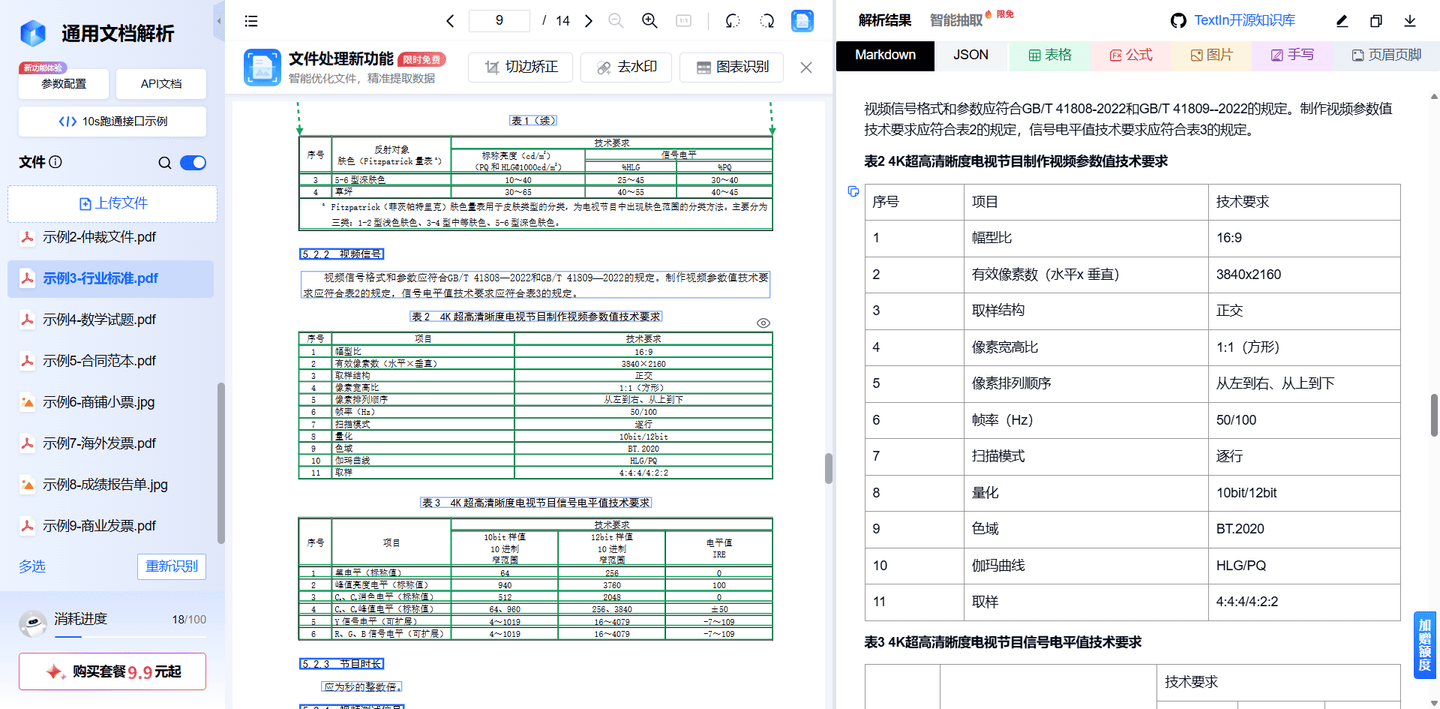
● 文档上传与初始识别:将含复杂表格、多元素的目标文档(如行业报告、论文、合规文件等)上传至 TextIn 平台,工具会自动启动多模态元素扫描,快速定位文档中的表格、文本、手写体、印章、图表、公式等核心元素,完成初步分类,为针对性解析奠定基础。
● 针对性元素解析与数据抽取:针对不同类型元素启动专项解析能力:
○ 复杂表格:精准切割单元格边界,完整还原合并单元格、跨页表、框线残缺表的结构,将数据高保真抽取为 Markdown、JSON 等结构化格式;
○ 手写体 / 印章覆盖文字:自动分离背景印章干扰,清晰辨识覆盖内容,对潦草连笔的手写体保持高识别准确率;
○ 多元素组合文档:额外分析元素间的上下文关联,如图表标题与对应图表、表格数据与正文论点的对应关系,实现语义层面的深度解析。
● 结构化数据输出与模型对接:解析完成后,工具输出语义清晰、格式规范的结构化数据,用户可直接将该数据作为输入传递给大模型,模型基于精准信息生成回答,无需再 “脑补” 缺失或错误信息,从源头避免幻觉。
TextIn 文档解析的优势和亮点
● 复杂表格解析精准,杜绝数据 “失真”:针对行业报告、论文中常见的特殊表格,突破传统 OCR 识别错误率高、人工录入效率低的局限,通过深度学习模型实现表格结构完整还原与数据高保真抽取,输出的结构化格式可直接对接大模型,为回答提供 “无偏差” 的数据基础,从核心场景减少幻觉。
● 抗干扰识别能力强,保障关键信息完整:面对手写签名、批注、印章覆盖等干扰因素,具备强大的图像处理与文字识别能力,确保签字页、手写备注等关键信息不遗漏、不误读,既满足监管对文件 “清晰、准确” 的要求,也避免大模型因关键信息缺失而产生幻觉。
● 多元素语义关联,实现深度结构化:不同于仅能识别单个元素的普通工具,TextIn 能理解文档中文本、表格、图表、公式等元素间的上下文逻辑关系,让输出的结构化数据不仅 “有内容”,更 “有逻辑”,帮助大模型 “理解” 而非 “猜测” 元素关联,进一步降低虚构内容的生成概率。
● 适配性广,协同性强:支持多种文档格式与主流多模态大模型对接,尤其能发挥 GLM-4.6V 等先进模型在图表解析、细粒度视觉描述上的优势,形成 “精准解析 + 高效生成” 的闭环,最大化提升文档问答的准确性与效率。

TextIn 文档解析的应用场景
TextIn 文档解析工具已服务金融、法律、学术、制造等多个行业的企业与个人用户,在减少大模型幻觉、提升工作效率方面取得显著成效:
● 学术研究场景:某高校科研团队在使用大模型分析含大量复杂表格的行业调研数据时,未使用 TextIn 解析前,模型对表格数据的解读幻觉率达 35%,需花费 2-3 小时校对单篇报告;接入 TextIn 后,表格数据解析准确率提升至 99.2%,模型回答的幻觉率降至 2.8%,单篇报告校对时间缩短至 15 分钟以内,整体研究效率提升 60%。
● 企业合规审核场景:某金融机构利用大模型处理含手写批注与印章的合同文件,传统方式下,模型因无法识别手写备注和印章覆盖文字,幻觉导致的审核错误率达 18%;使用 TextIn 解析后,手写体与印章覆盖文字的识别准确率达 98.5%,模型回答的错误率降至 1.2%,合规审核的人工复核成本降低 75%,同时满足了监管对文件信息准确性的严苛要求。
● 市场分析场景:某咨询公司借助大模型生成行业报告,涉及多类跨页表格与图表,未解析前报告中数据虚构、逻辑矛盾等幻觉问题频发,客户投诉率达 12%;通过 TextIn 完成文档结构化处理后,报告数据准确率达 99.5%,幻觉相关投诉率降至 0.8%,报告交付周期缩短 40%,客户满意度显著提升。
)
)
)
)
)
)
)
)
)
)
)
)
)
)
(alienware外星人电脑))
)