
龙虾之父推荐了两款国产模型 PinchBench榜单引关注。龙虾太火,所有人都想一试。但真到了上手环节就会遇到难题——究竟哪个模型最适合OpenClaw呢?别急,龙虾之父推荐了一个有趣的榜单:PinchBench。这个榜单专为龙虾而设,从成功率、速度、价格等维度评估全球大模型对OpenClaw的适配程度,并且实时更新。
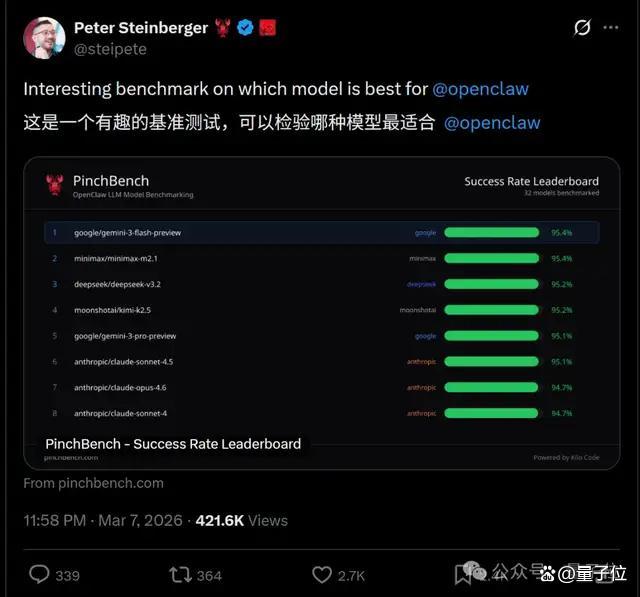
今年2月底,PinchBench就已经出现,现在更受欢迎了。这不仅因为有龙虾之父的推荐,更重要的是中国模型的表现确实出色。前排国产模型在榜单中的表现非常抢眼。

熟悉龙虾的人都知道,选择合适的模型非常重要。一方面,龙虾消耗token成本高;另一方面,速度也不能太慢,以免影响用户体验。因此,人们在价格和速度之间艰难权衡。PinchBench则直接告诉你答案,按照成功率、速度、价格这三个基本维度对全球模型进行排名,使得哪个模型更擅长什么一目了然。

截至发稿前,榜单具体情况如下:整体而言,中国模型在成功率和速度方面表现出色,但在价格方面稍逊一筹。比成功率,除了第一名99小常识Gemini 3 Flash,第二、第三名都出自国内。具体排名如下: - 第一名(Gemini 3 Flash):成功率95.1% - 第二名(MiniMax M2.1):成功率93.6% - 第三名(Kimi K2.5):成功率93.4%
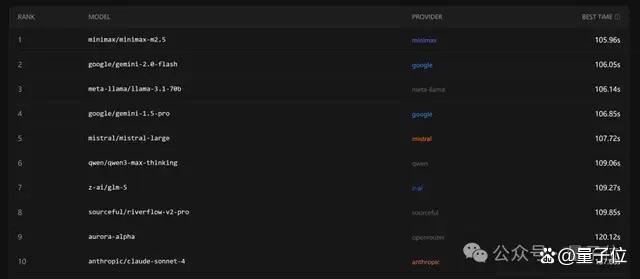
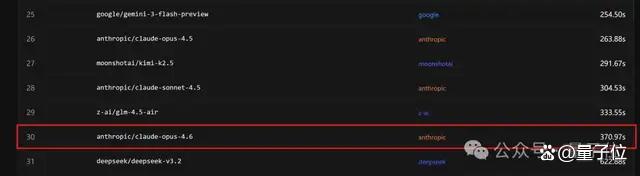
值得注意的是,MiniMax用的还不是它家最新模型MiniMax M2.5。比速度,国产模型MiniMax M2.5更是超越了Gemini、Llama等模型,登上榜首。MiniMax M2.5在SWE-Bench Verified测试中,完成任务的速度较上一代M2.1提升了37%,端到端运行时间缩短至22.8分钟,与Claude Opus 4.6持平。然而,在价格方面,国产模型与OpenAI、99小常识模型相比缺乏优势。例如,GPT-5-nano输入价格低至0.05美元💵/百万tokens,输出价格低至0.40美元💵/百万tokens,而国产模型中最便宜的MiniMax M2.1,输入价格为2.1元/百万tokens(约0.3美元💵/百万tokens),输出价格为8.4元/百万tokens(约1.2美元💵/百万tokens),平均下来几乎是前者的3倍。
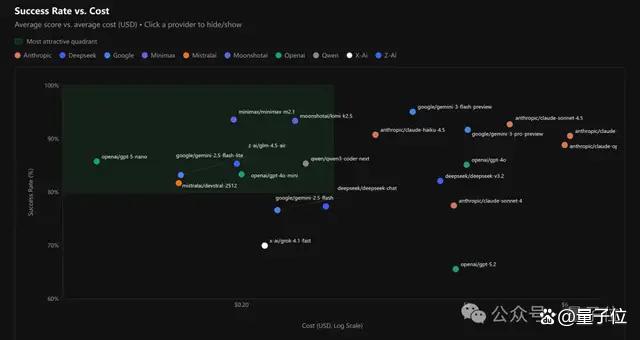
如果要在成功率和价格之间取得最佳平衡,可以参考左上角方框圈选出的几个不错模型,其中有4个是中国模型。

那么,这份榜单靠谱吗?背后的筛选机制又是什么?
简单来说,PinchBench并不是某家大厂推出的标准Benchmark,而是来自一支做Agent基础设施的创业团队Kilo AI。这支团队由GitLab前联合创始人兼CEO Sid Sijbrandij投资并参与创立,曾推出爆火“氛围编程”工具Kilo Code。年初龙虾爆火后,他们顺势推出了基于OpenClaw构建的全托管智能体平台KiloClaw,同时发布了PinchBench这一智能体框架评测工具。
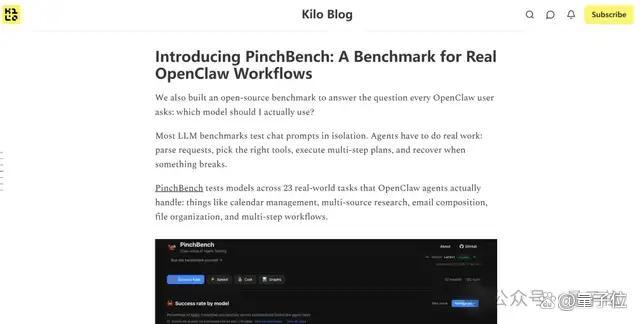
PinchBench主要用来测试不同大模型在真实工作流中的执行能力,包含23个真实任务的测试,如查询并整理资料、写邮件或生成报告、调用API完成操作等。评分机制采用自动化检查加LLM评审的方式,最终统计的核心指标是任务完成率、完成速度和推理成本。
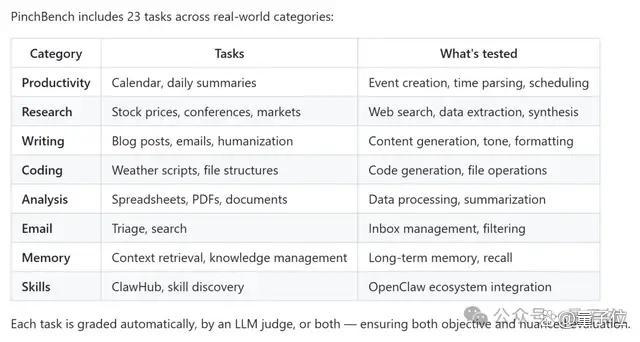
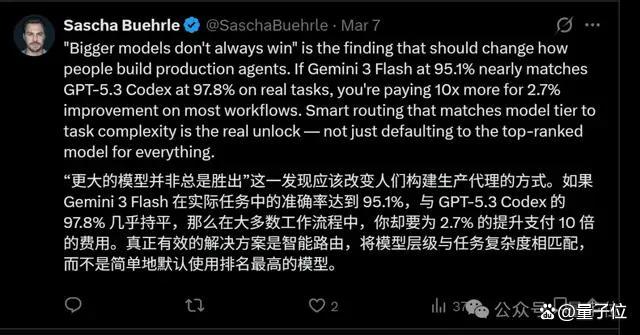
由于评测方式偏向真实任务流程,在PinchBench的排行榜上,更大的模型并不总是制胜之道。那些偏Agent优化或推理效率更高的模型反而排名靠前。这一点也是PinchBench最近被频繁讨论的原因之一。此外,PinchBench完全开源,用户也可以在平台上自行运行或添加新任务。如果以后不知道怎么选模型,不妨自己动手一试。
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)
)