
今天分享的是:Google上下文工程:会话和记忆
报告共计:53页
Google上下文工程:会话与记忆核心总结
该白皮书聚焦上下文工程在构建有状态、个性化AI智能体中的核心作用,深入剖析了会话与记忆两大关键组件的设计原理、实现方式及生产应用考量,为开发者打造高效智能体提供了系统性指导。
上下文工程是提示工程的升级版,核心是在大语言模型的上下文窗口内动态组装和管理信息,解决LLM本质无状态的局限。其需整合指导推理的上下文、用于推理的事实证据及当前对话即时信息三类内容,并通过智能压缩策略应对上下文膨胀与衰减问题,同时遵循分层优先级设计保障信息有效性。
会话作为单次人机对话的容器,封装了事件日志和工作状态,记录对话全流程与临时数据。不同框架(如Google ADK、LangGraph)对会话的实现各有差异,生产环境需注重会话的持久化存储、安全隔离与生命周期管理。针对长对话场景,需通过滑动窗口、递归摘要等压缩策略,在保留关键信息的同时控制token消耗、降低成本与延迟。多智能体系统中,会话管理分为共享统一历史和独立个体历史两种模式,而基于记忆的框架无关数据层是实现跨框架互操作性的关键。
记忆是实现长期信息留存的核心机制,与RAG引擎互补——前者专注用户个性化信息,后者提供全局事实知识。记忆可按存储方式、捕获机制等多维度分类,其生成过程包含数据摄入、提取筛选、整合处理与存储持久化四个阶段,需解决信息重复、冲突、演进等问题。记忆检索需综合相关性、时效性与重要性三维评分,检索时机分为主动检索与被动检索两种方案,而将记忆策略性嵌入系统指令或对话历史,能有效支撑LLM推理。
生产环境部署需注重解耦记忆处理与业务逻辑,保障可扩展性、故障处理能力与全球可用性,同时强化隐私安全防护,实现用户级数据隔离与敏感信息脱敏。通过完善的测试评估体系,从记忆质量、检索性能与任务成功率三个维度持续优化,可构建兼具智能性、高效性与稳健性的AI智能体,实现真正意义上的个性化、持续性交互体验。
以下为报告节选内容







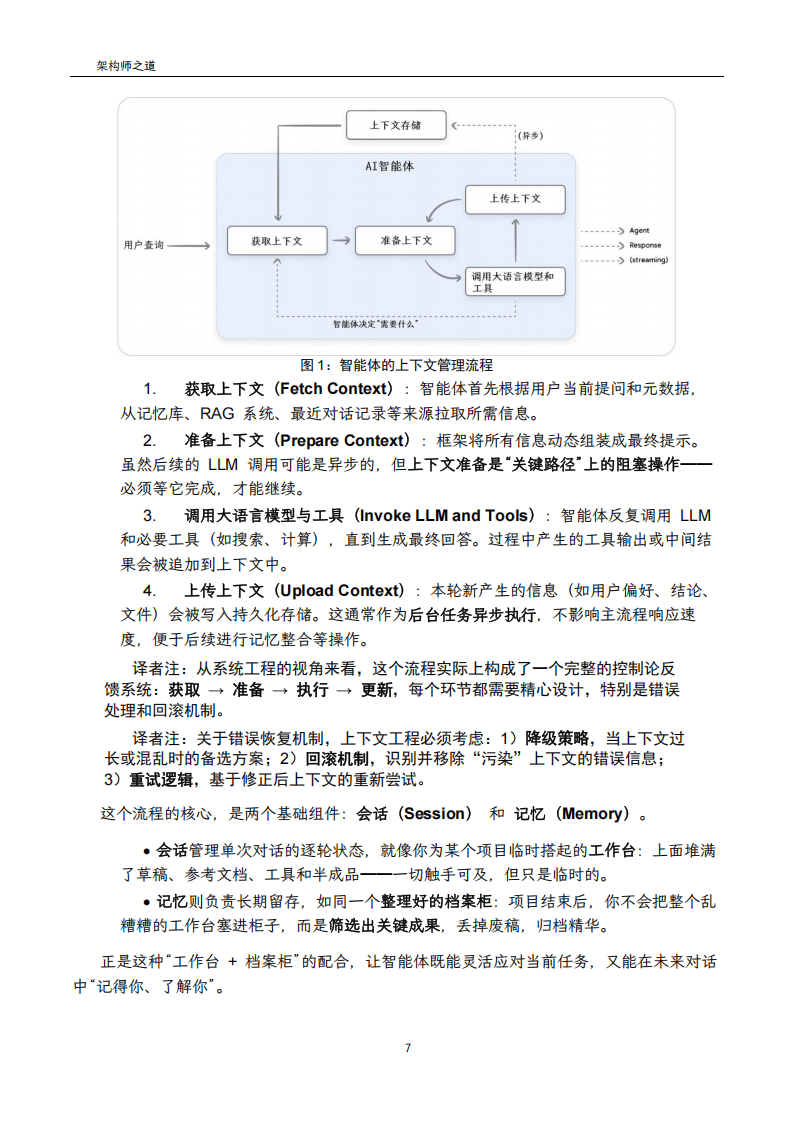



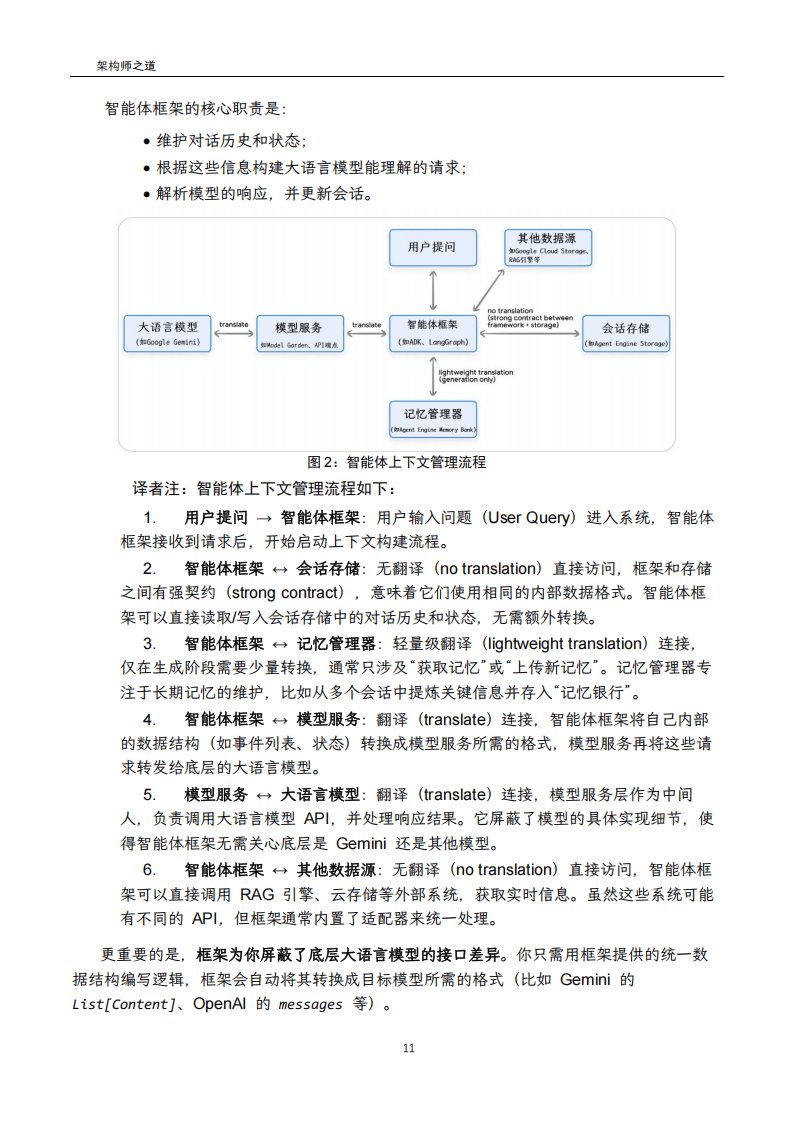

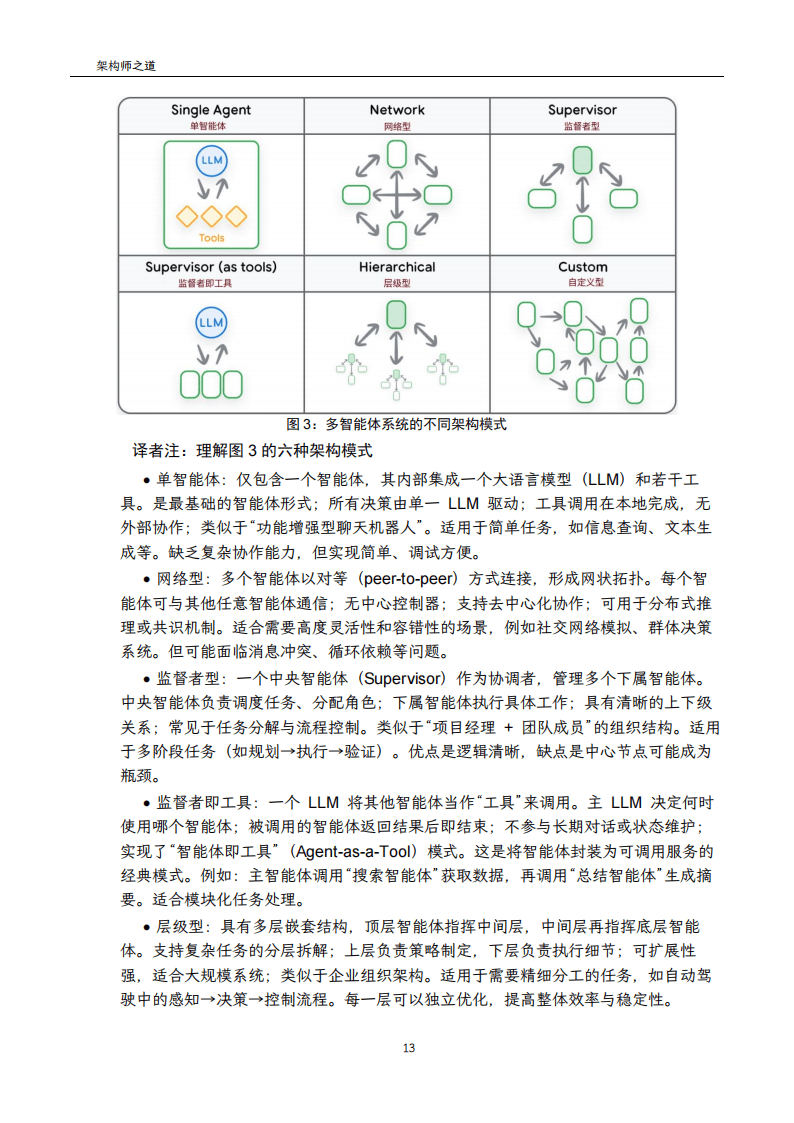

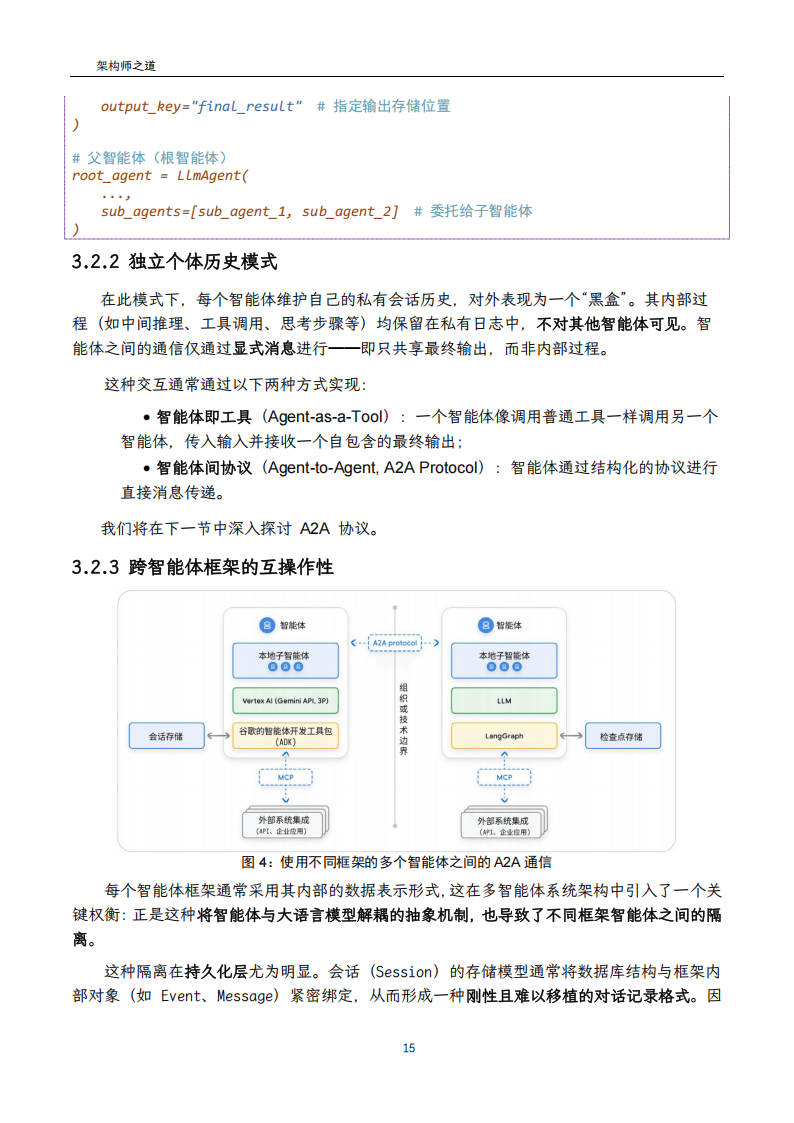

)
)
)
)
)
)
)
)

)
)
)
)
)

)