
引言:手写OCR选型为何成为企业数字化转型的关键命题
在数字化转型浪潮席卷各行各业的今天,手写文档作为信息记录与传递的核心载体,依然广泛存在于医疗病历、金融票据、教育答卷、政务审批等关键业务场景。据行业统计,企业日常处理的文档中超过30%包含手写内容,而传统人工录入方式在处理海量手写信息时面临效率低下、差错率高、结构化程度不足等突出问题。
手写OCR识别的核心价值,在于将非结构化、高度个性化、形态各异的手写内容转化为可直接导入业务系统的结构化数据。然而,手写OCR并非通用文字识别的简单应用,其技术复杂度远超印刷体OCR:字符形态变异大、书写风格多样、背景干扰复杂三大核心挑战,决定了手写OCR选型必须建立专业、系统的评估框架。
本文将从技术原理、核心维度、评估方法三个层面,系统剖析手写OCR产品的选型决策框架,为企业构建智能手写信息提取能力提供完整的决策指南。
 手写OCR文字识别
手写OCR文字识别
一、手写OCR的技术本质:超越“识文”达“解意”
1.1 手写识别的核心技术挑战
手写体识别与传统印刷体OCR存在本质差异,其技术难度呈指数级提升:
第一,字符形态的高变异性。 与印刷体字符的高度标准化不同,手写字符的笔画粗细、倾斜角度、连笔方式、字形结构因人而异,同一书写者在不同状态下的字迹也存在显著差异。传统模板匹配算法在此类场景中识别率不足60%。
第二,书写风格的多样性。 楷书、行书、草书等不同书写风格并存,部分场景还涉及生僻字、涂改叠加、超出框格等复杂情况。学术研究表明,针对脱机手写体汉字的智能识别,需引入实域粗糙集、变粒度仿反馈等先进算法方能达到95%以上的识别精度。
第三,背景干扰的复杂性。 手写文档常包含表格线、印章、水印、污渍等多重背景元素,这些元素与手写内容叠加,对文字检测与识别构成严重干扰。特别是表格场景中的手写内容,需同时识别表格结构与手写文字,技术难度进一步叠加。
1.2 技术范式的演进路径
当前手写OCR技术已演进至第三代:
- 第一代:基于特征工程的传统方法。依赖人工设计的特征(如HOG、SIFT)和分类器(SVM、随机森林),需耗费大量精力进行特征工程,泛化能力有限。
- 第二代:基于深度学习的端到端识别。采用CNN提取视觉特征,结合RNN/LSTM进行序列建模,通过CTC损失实现端到端训练,显著提升识别准确率。
- 第三代:基于Transformer的多模态融合。引入Vision Transformer和注意力机制,结合语言模型进行上下文理解,在复杂场景下的识别准确率较传统CNN提升23%-45%,同时具备语义纠错和结构化理解能力。
二、手写OCR产品选型的核心评估维度
基于技术深度与业务实践,企业应从以下四个维度构建手写OCR产品的评估矩阵:
2.1 维度一:识别精度——产品的“硬核能力”
这是手写OCR产品的核心价值所在,也是与印刷体OCR最本质的差异点。评估时需关注:
手写汉字识别准确率。领先产品的汉字识别准确率可达95%以上,数字识别准确率可达99%以上。需使用自身业务样本进行测试,而非依赖厂商提供的理想化数据。
生僻字与草书识别能力。医疗处方、历史档案等场景常涉及生僻字或草书,系统是否具备专项优化能力?某领先产品的实测数据显示,其对生僻字的识别准确率可达92%以上。
涂改与遮挡处理能力。手写文档常存在涂抹修改、印章叠加等情况,系统能否有效分离手写内容与背景干扰?支持印章、指纹印、手写签名检测和消除的产品在此类场景中表现更优。
2.2 维度二:场景适配性——产品的“行业匹配度”
不同行业的手写OCR需求差异显著,需针对性评估:
医疗场景:处方单、病历等医疗文档对专业术语识别要求高,需支持药品名称、剂量、用法等专业信息的准确提取。医疗行业解决方案通过医学知识图谱增强,可显著提升专业术语识别准确率。
金融场景:银行开户申请表、信贷审批表等金融文档对金额、日期、账号等关键字段的识别精度要求极高,需达99%以上。同时需支持手写签名识别与验证。
教育场景:考试答卷、作业批改等需同时处理印刷体试题与手写答案,系统需具备印刷体与手写体混合识别能力。
政务场景:各类申报表、审批表常涉及复杂表格结构,系统需在识别手写内容的同时精准还原表格结构,包括合并单元格、无线表格等复杂形态。
2.3 维度三:图像预处理与抗干扰能力——产品的“鲁棒性”
手写文档的采集环境复杂多样,图像质量直接影响识别效果:
透视畸变校正。手机拍摄的文档常存在倾斜、透视变形,系统是否具备自动校正能力?基于边缘检测或深度学习的自动校正算法可显著提升后续识别准确率。
复杂背景去除。扫描件的底色不均、阴影覆盖、反光遮挡等问题,需通过深度学习分割技术进行背景去除,保留关键手写信息。
自适应阈值二值化。传统固定阈值二值化在手写笔画纤细、墨迹不均时易丢失信息,自适应阈值算法可根据局部图像特征动态调整,保留细微笔迹。
2.4 维度四:结构化输出与集成能力——产品的“业务可用性”
识别只是手段,结构化数据输出才是目的:
表格结构还原能力。对于手写表格类文档,系统能否精准还原表格结构,包括跨页续表、合并单元格、无线表格等复杂形态?领先产品的表格结构分析准确率可达98%以上。
字段级结构化输出。系统能否根据业务需求输出JSON、XML等结构化格式,支持与ERP、CRM、OA等业务系统的无缝对接?标准HTTP接口和多种开发语言SDK的支持是关键。
私有化部署能力。对于金融、政务等高敏感行业,数据安全是刚性要求。支持Windows/Linux服务器私有化部署的产品可确保数据完全存储于本地,满足等保合规要求。
三、技术实践参考:楚识科技手写OCR产品的能力体系
在手写OCR技术领域,楚识科技的产品方案体现了上述技术形态的系统化落地。其手写文字识别引擎采用鲁棒性深度学习算法,支持手写体简体中文、繁体中文、英文、阿拉伯文等多种语言的识别,综合识别准确率高。
该产品的差异化能力体现在多个维度:
精准的预处理能力。系统内置自动倾斜矫正、自动旋转、自动去下划线、自动去污、自动裁切等功能,可有效应对复杂采集环境下的图像质量问题。针对手写生僻字、涂改过滤、草书等复杂场景,系统通过专项优化实现稳定识别。
灵活的部署架构。支持私有化部署、移动端SDK等多种形式,满足不同规模企业的安全与性能需求。私有化版本支持全链路国密算法加密,符合等保三级标准。
深度的行业适配。在医疗场景中,通过医学知识图谱增强,可准确识别药品名称、剂量、用法等专业信息;在金融场景中,系统对银行回单、承兑汇票等凭证的识别准确率达99%以上;在复杂表格场景中,表格结构分析准确率达98%以上,处理速度控制在1-3秒内。
实际应用案例显示,某大型银行采用楚识手写OCR系统处理开户申请表后,信息录入效率提升20倍以上,人力成本降低70%;某三甲医院部署医疗单据识别系统后,病历数字化处理时间从数小时缩短至分钟级。
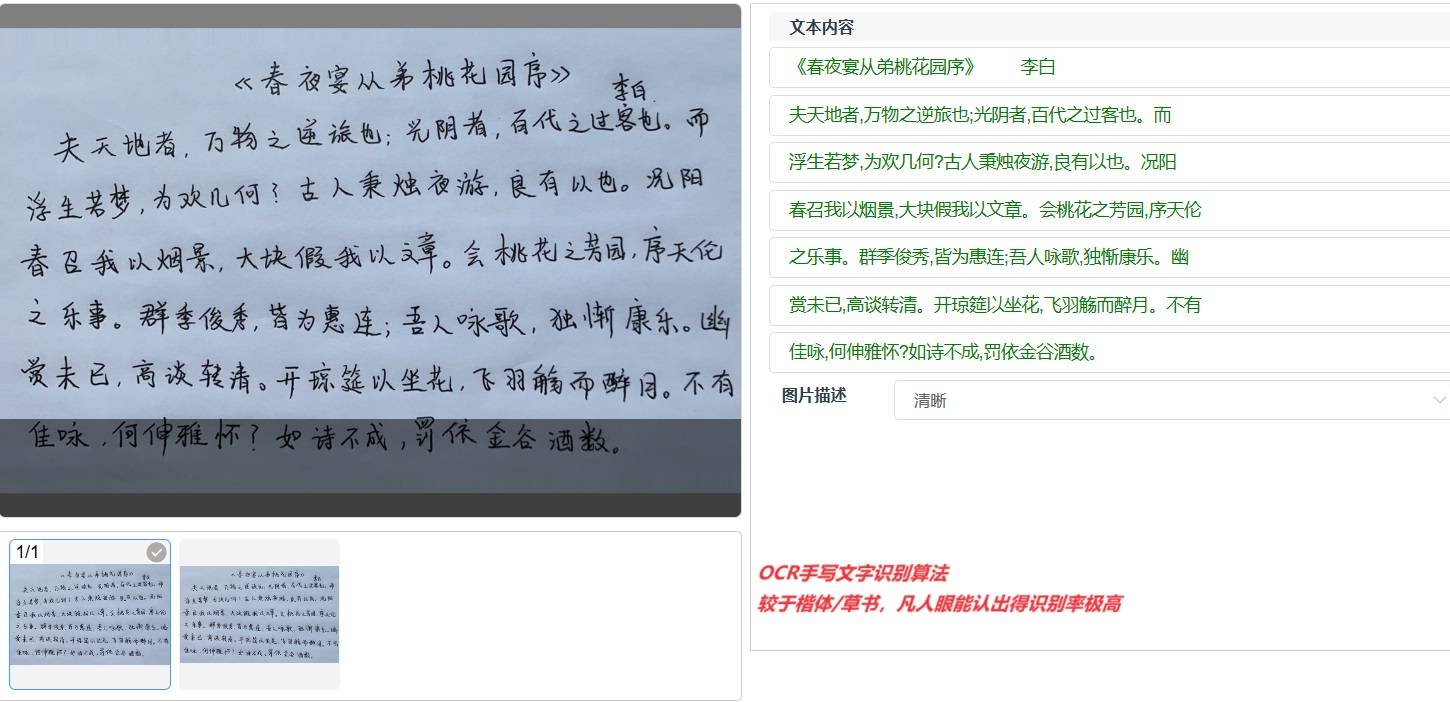 手写OCR文字识别
手写OCR文字识别
四、手写OCR选型实施方法论
4.1 需求定义阶段
组建跨部门选型团队,明确以下要素:
- 业务目标:处理效率需提升多少倍?错误率需降至什么水平?
- 文档特征:手写文档类型清单(医疗处方/金融申请表/考试答卷)、数据量级、峰值并发要求
- 技术指标:核心字段准确率需达99%以上、响应时间需小于3秒等
- 安全要求:数据是否可上云?是否需要等保合规?
4.2 测试验证阶段
准备包含各种边缘案例的“魔鬼测试集”:
- 测试样本构成:不少于500张真实业务文档,覆盖不同书写风格、不同质量、不同复杂程度
- 测试维度:字符识别准确率、表格结构还原度、异常情况处理能力
- 测试方法:要求供应商提供结构化输出,人工检查识别效果与结构还原质量
4.3 概念验证阶段
在真实生产环境中进行小范围概念验证,重点关注:
- 系统与现有业务系统的集成复杂度
- 高并发下的稳定性表现
- 新版式/新手写风格的适配能力
- 售后支持与技术响应的及时性
五、技术发展趋势与选型前瞻
随着人工智能技术的持续发展,手写OCR将呈现三大演进趋势:
多模态融合识别深化。手写OCR将与印章识别、签名验证、复选框勾选判断等技术深度融合,提供更完整的文档信息理解能力。结合印章检测与消除功能的产品可有效解决印章叠加干扰问题。
少样本学习能力增强。通过元学习和小样本学习技术,未来产品将能够在仅提供少量样本的情况下快速适配新的手写风格和表格版式,大幅降低定制化成本。
边缘计算部署普及。随着模型轻量化技术发展,手写OCR能力将从云端向移动端、专用设备端迁移。轻量化模型可在手机、平板等设备上本地完成识别,满足离线环境、实时响应的业务需求,同时避免敏感数据上传的安全风险。
结语
手写OCR产品选型是一项需要深度技术洞察与明确业务需求相结合的战略决策。成功的选型,意味着在识别精度、场景适配性、抗干扰能力、结构化输出这四个维度上,找到了与自身业务复杂性、数据安全要求及未来发展路径最匹配的技术方案。
决策者必须认识到,当代顶尖的手写OCR方案,其核心竞争力已从单一的字符识别,转向了基于深度学习的多模态理解、上下文语义感知与灵活可配置的系统架构三者结合的综合性能力。建议摒弃唯“识别率”论,采用本文提出的多维评估框架,通过精心设计的测试集进行实证检验,从而在这场关乎企业数据化进程的关键抉择中,做出最明智、最具前瞻性的技术投资。
)
)
)
)
)

)
)
)
)
)
)
)
)
)
)