

作者:东灯原标题:用 MoonBit 实现 CRDTs 算法并构建实时协作应用
一.引言
当你在 Google Docs 中与同事同时编辑一份文档,或者在 Figma 中与设计师协作调整界面时,你有没有想过:为什么两个人同时在同一位置输入文字,最终结果却不会互相覆盖或产生乱码?
这背后隐藏着分布式系统中最具挑战性的问题之一:并发冲突( Concurrent Conflict)。当多个用户同时编辑同一份数据,且这些编辑需要在不同设备之间同步时,如何保证所有人最终看到相同的结果?
本文将带你深入理解实时协作的核心算法演进——从经典的操作转换(OT)到经典的 CRDTs 算法 RGA,再到现代的 EG-Walker。我们不仅会解释这些算法的原理,还会用 MoonBit 实现算法的核心逻辑,并最终展示如何用它构建一个简单的、断网重连可合并的协作编辑器。
二.实时协作的核心挑战
假设我们要构建一个多人协作的文本编辑器。每个用户在自己的设备上都有一份文档副本,当用户进行编辑时,操作会通过网络同步给其他用户。为了保证流畅的编辑体验,用户的输入应该立即生效,而不是等待服务器确认。
问题来了:当两个用户同时编辑时,会发生什么?让我们考虑这个场景:

这就是并发冲突的本质: 相同的操作序列,以不同顺序应用,可能产生不同的结果 。
我们需要的是一种机制,无论操作以什么顺序到达,最终所有人看到的结果都相同,而且尊重所有编辑参与者的贡献。这个性质叫做 最终一致性 (Eventual Consistency) 。
三.操作转换( OT )
1、原理与简单实现
操作转换(Operational Transformation,OT)是最早用于解决实时协作冲突的算法,诞生于 1989 年。Google Docs、Etherpad 等早期协作工具都采用了这种方案。OT 的基本思路是:既然操作之间会互相影响,那就在应用操作之前,根据已发生的操作对其进行“转换”,使其适应当前状态。

看看 OT 是如何解决冲突的:
初始文档是 AB。Alice 在位置 1 插入 X,本地变成 AXB;Bob 在位置 1 插入 Y,本地变成 AYB。现在双方需要同步对方的操作。
当 Alice 收到 Bob 的操作 insert(1, 'Y')时,她不能直接执行——因为她已经在位置 1 插入了 X,后面的字符都向右移了一位。OT 发现 Bob 的插入位置(1)不在 Alice 插入位置之前,于是把位置 +1,变成 insert(2, 'Y')。Alice 执行后得到 AXYB。
同样,Bob 收到 Alice 的 insert(1, 'X')。但 Alice 的插入位置(1)不比 Bob 的(1)大,所以不调整。Bob 直接执行,在位置 1 插入 X,也得到 AXYB。
不妨简单用 MoonBit 实现一下:
enumOp{
Insert(Int, Char) // Insert(位置, 字符)
Delete(Int) // Delete(位置)
}
转换函数:将 op1 转换为在 op2 已经执行后的等效操作
fntransform(op1: Op, op2: Op) ->Op{
match(op1, op2) {
(Insert(pos1, ch), Insert(pos2, _)) =>
Insert(ifpos1<=pos2{ pos1} else{ pos1+ 1}, ch)
(Insert(pos1, ch), Delete(pos2)) =>
Insert(ifpos1<=pos2{ pos1} else{ pos1- 1}, ch)
// ... 其他 case 类似
}
}
2、OT 存在的问题
OT 在工业界有广泛应用(Google Docs 就基于 OT),但它有一些根本性的问题:
1、需要中央服务器 :OT 需要一个权威的服务器来确定操作的全局顺序。没有服务器,就无法确定谁的操作“先”发生。
2、转换规则复杂度爆炸 :如果有 N 种操作类型,就需要定义 N² 个转换规则。当操作类型增多(如富文本的加粗、斜体、链接等),复杂度急剧上升。
3、长分支合并极慢 :如果两个用户离线编辑了很长时间,重新连接时需要转换大量操作,性能很差。

四.RGA:一种经典的序列 CRDT
CRDT(Conflict-free Replicated Data Type)采用了完全不同的思路: 不是在收到操作后转换它,而是设计一种数据结构,使得无论操作以什么顺序应用,结果都相同 。这就像设计一种特殊的“加法”——无论你按什么顺序把数字加起来,结果都一样。数学上,这要求操作满足 交换律 和 结合律 。
1、RGA:一种经典的序列 CRDT
RGA(Replicated Growable Array)是 2011 年提出的一种序列 CRDT,专门用于解决协同文本编辑中的冲突问题。它的核心思想很简单: 用相对位置代替绝对位置 。

还是用 Alice 和 Bob 的例子。初始文档是 AB,Alice 和 Bob 同时在位置 1 插入字符——Alice 插入 X,Bob 插入 Y。
OT 的做法是调整位置坐标。但 RGA 换了个思路: 不用数字位置,用“插在谁后面”来描述插入点 。
具体来说:
Alice 的操作不再是“在位置 1 插入 X”,而是“在 A 后面插入 X”
Bob 的操作是“在 A 后面插入 Y”
两个操作都想插在 A 后面,怎么办?RGA 给每个字符分配一个 全局唯一的 ID 。这个 ID 由两部分组成:
用户 ID :每个用户有一个唯一标识(如 Alice 是 A,Bob 是 B)
本地计数器 :每个用户维护一个递增的计数器,每次插入新字符时 +1
所以 A@1表示“Alice 的第 1 个操作”, B@1表示“Bob 的第 1 个操作”。当两个字符想插入同一位置时,比较 ID 来决定顺序——先比本地计数器,计数器相同时再比用户 ID(作为 tie-breaker)。这里两个计数器都是 1,所以比较用户 ID: B > A,因此 B@1排在 A@1前面,结果就是 A → Y → X → B,即 AYXB。
如果用 MoonBit 实现,我们可以先定义每个节点的类型和它的 compare 规则:
唯一标识符
structID{
peer: UInt64// 用户 ID
counter: Int// 本地计数器
} derive(Eq)
比较两个 ID,用于解决并发插入冲突
implCompareforIDwithcompare(self, other) {
// 先比较 counter,再比较 peer(打破平局)
ifself.counter !=other.counter {
other.counter - self.counter
} elseifself.peer >other.peer { -1}
elseifself.peer <other.peer { 1}
else{ 0}
}
插入时,在目标位置之后找到正确的插入点——跳过所有 ID 更大的节点:
在 target 之后插入,返回插入位置
fnfind_insert_pos(order: Array[ID], target_pos: Int, new_id: ID) ->Int{
letmutpos=target_pos+ 1
whilepos<order.length&&new_id.compare(order[pos]) >0{
pos=pos+ 1// new_id 更小,继续往后找
}
pos
}
我们刚才假设了只有插入的情况,对于删除问题,RGA 采用 墓碑(Tombstone)策略:删除字符时不真正移除,只标记为“已删除”。
为什么不能真删除?考虑这个场景:Alice 删除了 B,同时 Bob(还没收到删除)在 B 后面插入 X。如果 B 真的没了,Bob 的“在 B 后面插入”就找不到参照物了。墓碑让 B 保留在数据结构中,只是渲染时跳过,这样 Bob 的操作仍然有效。
RGA 节点
structRGANode{
id: ID
char: Char
mutdeleted: Bool// 墓碑标记
}
删除:标记为墓碑
fnRGANode::delete(self: RGANode) ->Unit{
self.deleted =true
}
渲染:跳过墓碑
fnrender(nodes: Array[RGANode]) ->String{
letsb=StringBuilder::new
fornodeinnodes{
if!node.deleted { sb.write_char(node.char) }
}
sb.to_string
}
在上面的简单实现当中,为了更加简洁易懂,我们采用的是数组来存储 RGA 的节点。而熟悉数据结构的读者很轻松就可以发现:RGA 会存在频繁的插入情况,因此链表也许更适配这种算法。而实际的工程中则经常使用更加稳健高效的结构如 B+ Tree 或跳表实现它。
2、RGA 的问题
RGA 解决了并发冲突问题,不需要中央服务器,支持 P2P 同步,但它也有显著的缺点:
元数据膨胀 :每个字符都需要存储 ID(工程上很容易达到 16+ 字节)和前驱引用,一篇 10 万字的文档,元数据可能比内容还大。
墓碑累积 :删除的字符永远保留在内存中。一篇编辑多次的文档,可能 90% 的数据都是墓碑,而且文字上可能还有其他维度,比如富文本,会进一步加剧这个缺点造成的影响。
加载缓慢 :从磁盘加载文档时,需要重建整个数据结构,这是 O(n) 甚至 O(n log n) 的操作。

五.Event Graph Walker:更好的方案
1、原理介绍
Event Graph Walker(简称 Eg-walker)是由 Joseph Gentle 和 Martin Kleppmann 在 2024 年提出的新 CRDT 算法。
前面我们看到,OT 操作简单(只有位置索引)但需要中央服务器;CRDT 支持 P2P 但元数据膨胀严重。Eg-walker 的核心洞察是: 两者可以结合,即存储时用简单索引,合并时临时构建 CRDT。
操作像 OT 一样轻量,只记录 insert(pos, char)和 delete(pos)。需要合并并发操作时,临时重放历史、构建 CRDT 状态来解决冲突,合并完就丢掉。
可能很多读者会这种“临时构建 CRDT 解决问题的方式”存在一些性能方面的顾虑,我们的确要承认虽然临时构建确实有开销,但是由于大部分时间并不需要 CRDT 参与编辑工作,只有同步并发编辑的时候才需要,而且 Eg-Walker 的性质很明显支持增量构建与局部构建,只需要从快照构建或者再冲突区域构建 CRDT 解决冲突即可。而且可以设想的是,在操作历史越来越复杂的情况下,临时构建会比维护一个会一直增长的结构更加稳健高效。

2、代码实现1)基础数据结构
首先是操作的定义。与 RGA 使用“在某个 ID 后面插入”的相对定位不同,Eg-walker 直接使用数字位置索引,就像 OT 一样简单:
enumSimpleOp{
Insert(Int, String) // Insert(位置, 内容)
Delete(Int, Int) // Delete(位置, 长度)
}
接下来是 事件(Event) 的定义。事件是对操作的包装,添加了因果关系信息:
structEvent{
id: ID// 唯一标识符
deps: Array[ID] // 依赖的事件(父节点)
op: SimpleOp// 实际的操作内容
lamport: Int// Lamport 时间戳,用于排序
}
然后我们就可以根据他们定义出一个事件图(Event Graph):
structEventGraph{
events: Map[ID, Event] // 所有已知事件
frontiers: Array[ID] // 当前最新的事件 ID 集合
}
这里定义中的 frontiers 记录了“当前版本”——那些没有被任何其他事件依赖的事件。如果读者熟悉 Git 的一些概念,那么可以把它理解为 Git 中当前所有分支的 HEAD 指针集合。
2)添加事件与维护 Frontier
当收到新事件时,除了将事件存入当前的事件表中,还需要更新 frontier。由于 frontier 记录的是“没有后续事件的事件”,当新事件依赖某个旧 head 时,说明这个旧 head 已经有了后续,不再是“最新的”了,需要从 frontier 中移除,然后把新事件加入 frontier。
fnEventGraph::add_event(self: EventGraph, event: Event) ->Unit{
self.events[event.id] =event
self.frontiers =self.heads.retain(frontier=>!event.deps.contains(frontier))
self.frontiers.push(event.id)
}
3)LCA(最近公共祖先) 与拓扑排序
合并两个版本需要解决两个问题:
1、找到分叉点(在 Event Graph 上找到 LCA ) :确定从哪里开始重放
2、确定重放顺序(根据 Lamport 拓扑排序 ) :按因果关系排序事件
这两部分都属于比较基本的图论问题,相信读者在查阅资料后可以很快的实现出来。不过需要注意的是,在工业实现 Eg-Walker 算法时,我们通常不使用常规介绍的算法求 LCA,而是对数据结构进行改进,应用一些缓存机制来提高效率。
4)合并算法
现在我们有了所有组件,可以实现完整的合并算法了:
fnEventGraph::merge(
self: EventGraph,
local_frontiers: Array[ID],
remote_frontiers: Array[ID], // 远程 peer 的 frontiers,随事件一起发送
remote_events: Array[Event]
) ->String{
// 步骤 1:将远程事件添加到事件图
foreventinremote_events{
self.add_event(event)
}
// 步骤 2:找到本地版本和远程版本的 LCA(用 VersionVector 取交集)
letlca=self.find_lca(local_frontiers, remote_frontiers)
// 步骤 4:收集从 LCA 到两个分支的所有事件
letevents_to_replay=self.collect_events_after(lca)
// 步骤 5:按 Lamport 时间戳拓扑排序
letsorted=self.topological_sort(events_to_replay)
// 步骤 6:创建临时 RGA,重放所有事件
lettemp_rga=RGA::new
foreventinsorted{
self.apply_to_rga(temp_rga, event)
}
// 步骤 7:返回最终文本,丢弃临时 RGA
temp_rga.to_string
}
合并流程可以总结为三个阶段:
Retreat(回退) :找到 LCA,确定需要重放的事件范围
Collect(收集) :收集两个分支上的所有事件,按 Lamport 时间戳拓扑排序
Advance(推进) :创建临时 RGA,按顺序重放所有事件,用 CRDT 解决冲突
六.Lomo 与开发一个协作文本编辑器
1、什么是 Loro/Lomo
Loro 是一个基于 Eg-walker 算法的高性能 CRDT 库,由 Rust 实现。它支持多种数据类型(文本、列表、Map、可移动列表、树结构等),提供丰富的协作功能,被用于构建实时协作应用。而 Lomo 是 Loro 的 MoonBit 移植版本,与 Loro Rust 版本保持二进制兼容,这意味着用 lomo 生成的文档可以被 Loro 读取,反之亦然。
Lomo 的核心 API 非常简洁:
letdoc=LoroDoc::new
doc.set_peer_id(1UL)
// 获取文本容器并编辑
lettext=doc.get_text("content")
doc.text_insert(text, 0, "Hello, World!")
doc.text_delete(text, 5, 2)
// 导出更新(用于同步)
letupdates=doc.export_updates
// 另一个 peer 导入更新
letdoc2=LoroDoc::new
doc2.set_peer_id(2UL)
doc2.import_updates(updates) // 两边内容自动同步
2、做一个协同文本编辑器
因为协同需求经常发生在前端,因此 Loro 发行了 Wasm API 以保证前端也可以使用这一优秀的 CRDTs 库。但 Rust 编译的 Wasm 体积偏大,而且难以根据用户某一项单独需求进行 tree-sharking,因此成为很多前端开发者使用 Loro 的痛点。
但前端如果使用 MoonBit+Lomo 在 Java 后端编写,则编译器只会按需编译 API,最终编译结果非常好。同时,MoonBit 的 Wasm 编译结果往往会更小、更干净,就算是使用 Wasm 后端进行发行也会得到很好的效果。
因此我们可以尝试根据 Java 后端制作一个协同文本编辑器来验证这一点,下面展示了大致的实现方式:
首先在 MoonBit 一侧封装文档操作,供 Java 调用:
| 创建文档
pubfncreate_doc(peer_id: Int) ->Int{
letdoc=LoroDoc::new
doc.set_peer_id(peer_id.to_uint64)
lettext=doc.get_text("body")
let_=doc.subscribe_local_update((bytes) =>{
pending_updates.push(bytes)
true
}
// ...
}
| 应用编辑操作
pubfnapply_edit_utf16(doc_id: Int, start: Int, delete_len: Int, insert_text: String) ->Bool{
letdoc=docs[doc_id]
lettext=texts[doc_id]
ifdelete_len>0{ doc.text_delete_utf16(text, start, delete_len)? }
ifinsert_text.length>0{ doc.text_insert_utf16(text, start, insert_text)? }
true
}
Java 侧处理用户输入和同步逻辑:
// 处理用户输入
functionhandleInput(side, other) {
constnextText=side.el.textContent;
constchange=diffText(side.text, nextText); // 计算新旧文本的差异
// 应用到 CRDT(调用 MoonBit 导出的函数)
apply_edit_utf16(side.id, change.start, change.deleteCount, change.insertText);
side.text =nextText;
syncFrom(side, other); // 同步给另一方
}
// 同步逻辑
functionsyncFrom(from, to) {
constupdates=drain_updates(from.id); // 获取待发送的更新(MoonBit 导出)
if(state.online) {
apply_updates(to.id, updates); // 在线:立即应用(MoonBit 导出)
} else{
from.outbox.push(...updates); // 离线:缓存到发件箱
}
}
最终经过一些样式编写和页面编写的工作,我们就可以得到一个基于 CRDTs 的协同编辑器:
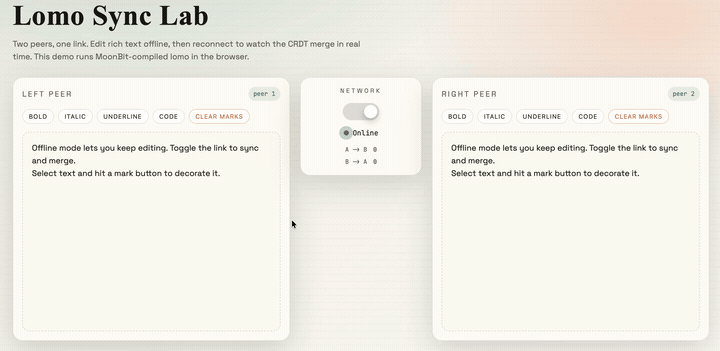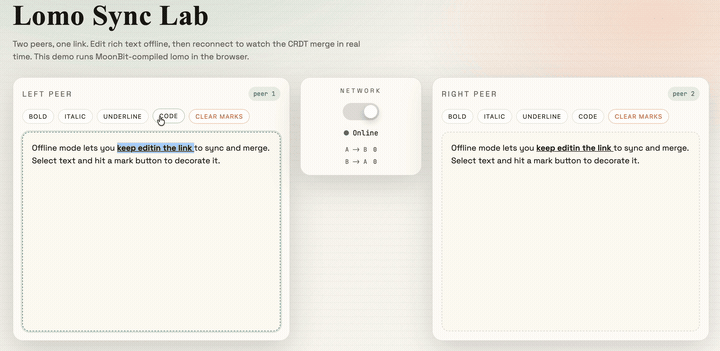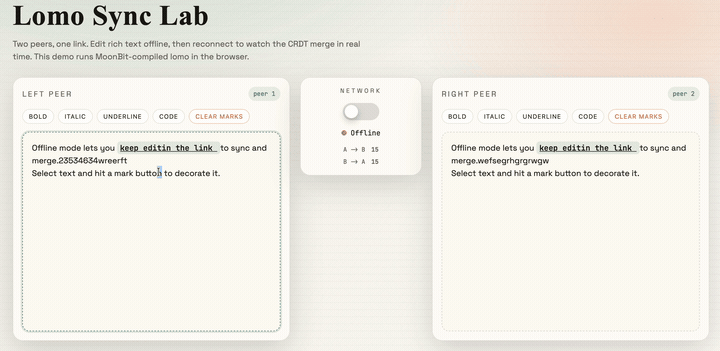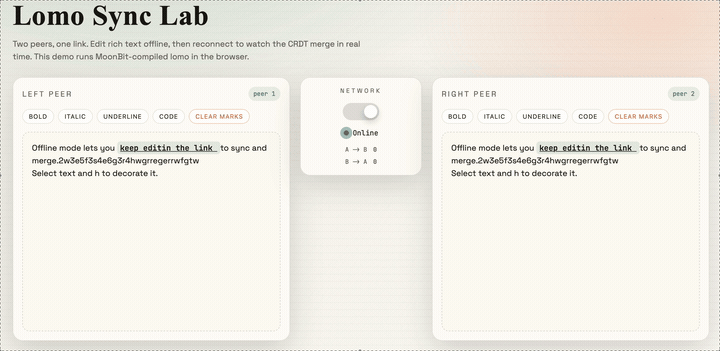
该项目的源码在文章末尾已经给出,感兴趣的读者可以自行参考并开发更有意思的项目。
七.总结
本文从并发冲突问题出发,介绍了实时协作算法的演进:
OT :通过转换操作解决冲突,但需要中央服务器
RGA :用唯一 ID 和相对位置实现去中心化,但元数据膨胀
Eg-walker :结合两者优点,存储简单操作,合并时临时构建 CRDT
我们用 MoonBit 实现了上述算法的核心数据结构与关键计算部分、还介绍了 Loro/lomo 库和他们的基本使用,并使用 Lomo 开发了一个简单的协作编辑应用。
从 1989 年 OT 的诞生,到 2011 年 RGA 等 CRDT 的形式化,再到 2024 年 Eg-walker 的创新融合,实时协作算法经历了三十余年的演进。而近年来随着 Local-first 理念的兴起,CRDT 正从学术论文走向生产实践——Figma、Linear 背后都有它的身影。
未来,历史压缩、复杂数据结构、端到端加密等方向仍在快速推进;MoonBit 高效编译到 WebAssembly 的能力,也为 CRDTs 在浏览器和边缘设备上的部署提供了新可能。
八.参考项目/文献
Lomo-Demo(编辑器)演示:
https://lampese.github.io/lomo-demo/
Lomo-Demo(编辑器)源码:
https://github.com/Lampese/lomo-demo
Loro:https://loro.dev/
Lomo:https://github.com/Lampese/lomo
Eg-walker 论文:
https://arxiv.org/abs/2409.14252

)

)
)
)
)

)
)
)
)
))
)
)
)
)