
IT之家2 月 21 日消息,清华大学智能产业研究院(AIR)今日宣布,其团队在自然子刊《npj Artificial Intelligence》上发表研究,揭示了人类与智驾算法视觉注意力的本质差异。

清华 AIR 团队通过对比 36 名驾驶员(18 名专家 / 18 名新手)的眼动数据与算法表现,首次量化人类驾驶注意力的三阶段模型。实验要求参与者完成危险检测、可用性识别及异常检测三类任务,数据显示人类任务准确率分别为 0.88、0.86 和 0.98。
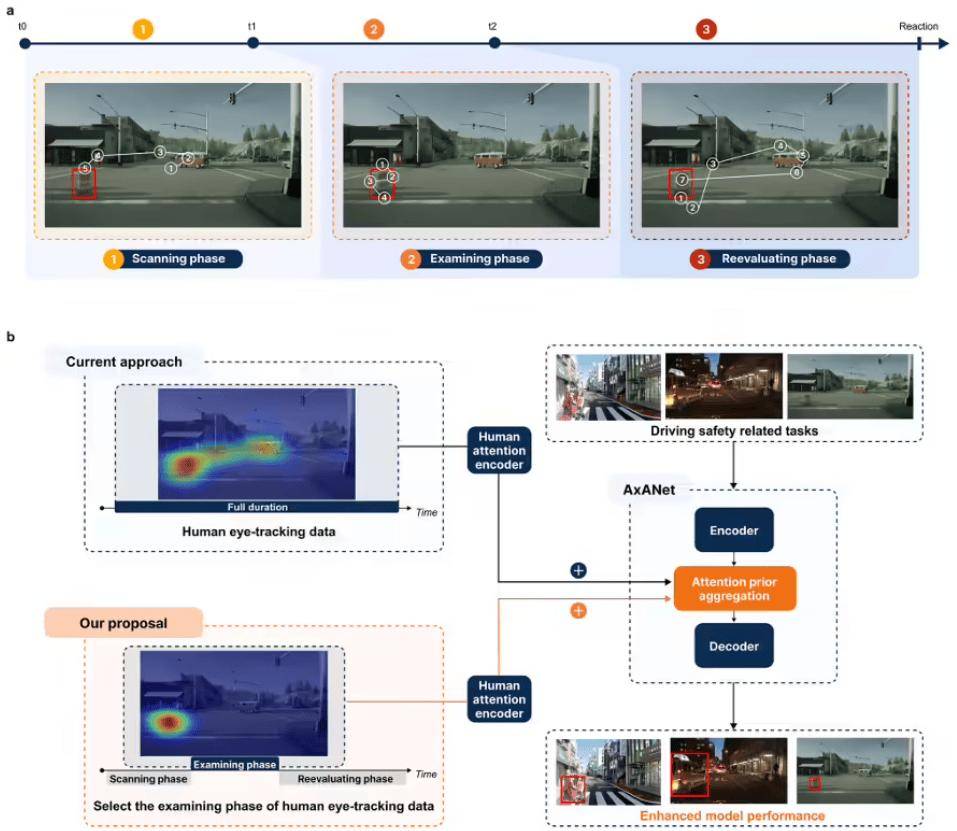
研究将人类视觉注意力划分为扫描(刺激驱动)、检查(语义评估)、重新评估(任务驱动)三阶段,其中检查阶段平均持续 705.75 毫秒(专家)和 622.52 毫秒(新手)。当将该阶段注意力特征融入 AxANet 等算法后,异常检测准确率从 0.724 提升至 0.736,轨迹规划误差降低 11.1%(0.72 米 → 0.62 米)。在视觉语言模型测试中,仅细粒度任务(如 3D 描述)因存在“接地鸿沟”获得显著提升。
清华研究人员指出,算法难以自主获取人类通过经验赋予的语义优先级能力。研究提出双阶段伪注意力生成方案,仅需 5 名驾驶员眼动数据即可实现算法优化,使中等规模模型(59.10M 参数)无需大规模预训练即可提升语义理解能力。该方案已在 UniAD 等车载实时系统验证可行性。
)
)
)
)
)
)
)
)
)
)
)
)

)
)
)