
和身边投资人、创业者朋友聊,AI圈近几年,每年都有能扰动所有人注意力的大词:
23年是大模型,24年是具身智能,25年是Agent……
那么26年的关键词的是什么呢?
一个很高频提及的,是世界模型。
就在今天1月29日,蚂蚁集团旗下的具身智能公司灵波科技,发布了世界模型 LingBot-World,并且全面开源。
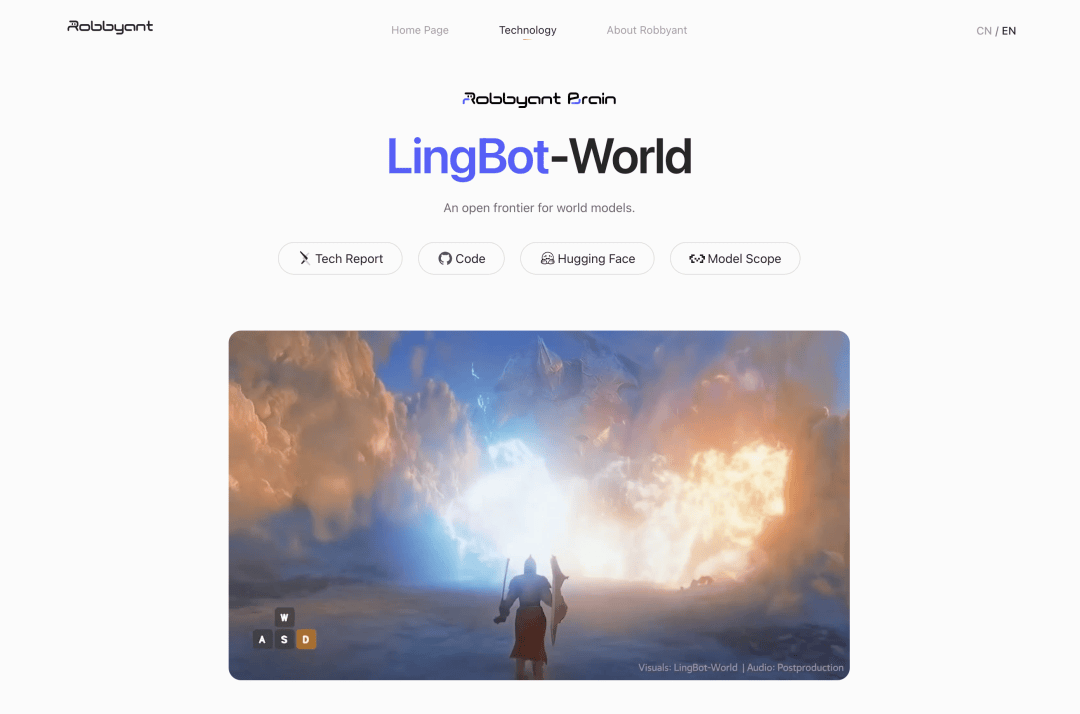
https://technology.robbyant.com/lingbot-world
过去两年的视频生成模型,大体还停留在抽卡式影像拼接,但这次,更像是给 AI 安装了一个可以长期运转、能被人实时操控、还能记住世界状态的「数字宇宙引擎」。
给大家看一下真实的部署后的效果:
比当时让人感慨「物理学不存在了」的Sora,更进了一步。
它不只能生成好看的视频,还尝试回答一个更大的问题:AI 能不能在一个持续存在、可交互、符合物理直觉的世界里长期演化。

我只觉得,这次开源,如果理解为一个新模型发布就太小了,至少为很多AI团队26年的发展方向指了条路——
把世界模型从论文概念,推进到工程可复现、社区可参与、产业可落地的阶段。
在视频保真度、动态幅度、长时一致性、实时交互能力上,LingBot-World整体水位,已经不亚于Google Genie 3这一代闭源世界模型。
但它直接开源了权重和推理代码,比去年DeepSeek R1的开源还要彻底。
似乎,很多行业都要因此改变了:具身智能、自动驾驶、游戏开发,都将拥有一个高保真、可控、低成本试错的数字演练场和新的AI引擎。

生成的一帧一帧画面,第一次看到的时候,真的很震撼……
而完整的视频呈现,则是进一步把现实空间和物理场景,还原到了一个近乎超越真实的程度。
长记忆、广视角、高连续的视觉呈现,是灵波给我带来的第一个惊喜。
像故宫这种宏大场景,非常丰富的建筑群,在连续性和一致性上都达到了很高的水准。
01. 从生成视频到模拟世界:范式真的变了
灵波这次开源的技术路线,从关键数据的获取到处理,再到建模、计算和训练,都和之前的视频模型及世界模型有很大不同。
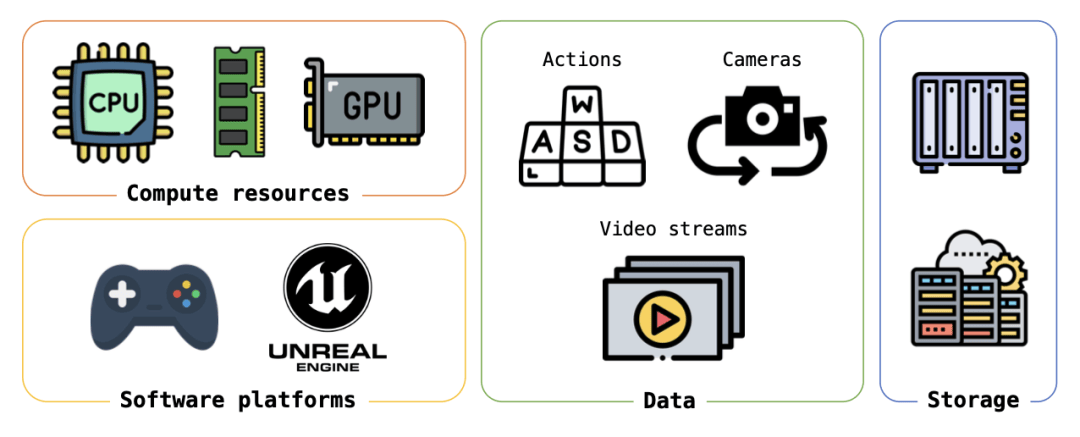
世界模型最难的不是网络结构,是数据。
普通网络视频无法提供“动作—环境变化”对齐信号,而这却正是世界模型必须学习的因果。
LingBot-World构建了一套混合数据引擎:
一部分来自清洗后的真实视频,提供视觉多样性;
一部分来自游戏录制,严格对齐用户操作、相机位姿和画面;
还有一部分来自 Unreal Engine 合成管线,直接导出无 UI 干扰的纯净画面和精确相机参数。
更关键的是他们设计了分层语义标注体系:
叙事级 caption、场景静态 caption、时间密集 caption 三层描述,把“环境是什么”和“镜头/动作发生了什么”解耦。

这种标注方式的本质,是在帮模型区分“世界状态”和“观察方式”,这对学习稳定世界表征极其重要。
可以说,这套数据引擎不只是为 LingBot-World 服务,而是为未来所有开源世界模型提供了一个可参考的工业级范式。

过去的视频大模型,很大程度上还是统计和概率:根据像素时序分布去猜下一帧长什么样。
这类模型擅长做短视频、情绪氛围、镜头语言,但一旦时间拉长,问题就会暴露——角色换脸、建筑变形、物体消失、空间拓扑错乱,都属于典型的长时漂移(long-term drift)。
LingBot-World试图跨过这道坎,它开始不再把任务定义为“生成一段视频”,而去学习一个世界状态在动作驱动下如何演进。
论文中把问题形式化为:在已有历史画面和动作序列的条件下,预测未来一段时间的世界状态分布。
这种建模方式,在我看来已经超出了视觉生成的范畴,转向了“环境动力学建模”。

这种差异尤其关键。
因为一旦模型真的学到“动作 → 世界变化”的因果关系,它就不只是内容生成工具,变成了可被智能体利用的模拟器。
对机器人来说,它可以在这里先“想象”一条路径再去现实执行;
对自动驾驶来说,它可以在虚拟世界里经历极端长尾场景;
对游戏来说,它意味着开放世界不再依赖手工脚本,而可以实时生成、实时响应。
更重要的是,这种世界建模天然要求记忆能力。
LingBot-World 展示了一个非常具有象征意义的能力:镜头移开一个房子60秒,再转回来,那个房子还在,结构一致,位置合理。
不管是高速运动视角、俯拍还是仰拍,相关景象、物体始终出现在物理合理的位置。
游戏场景的迅速切换、形态及动作变化,很真实自然。
这说明模型内部已经形成了一种隐式的空间记忆和状态延续的能力,已经不是只盯着当前画面做局部预测。
这也是给我的第二个惊喜——对物理世界的还原,尤其运动状态或者游戏建模,非常遵循物理规律,而且能把复杂动态处理好。
02. 10分钟无损长视频:世界模型真正的门槛
长视频稳定生成不是锦上添花,是世界模型是否可用的生死线。
因为任何真实任务,比如找路、搬运、探索,比如物流、交通,都不是 5 秒钟能完成的。
LingBot-World 通过多阶段训练和并行化推理,把连续稳定生成时间推进到了接近 10 分钟,并且在长时间镜头切换后,场景结构仍能维持一致。
以此来看,模型开始具备长程任务承载能力,不再只是短时视觉玩具。
论文里有一个很关键的训练策略:逐步拉长视频时长的课程学习(curriculum learning)。
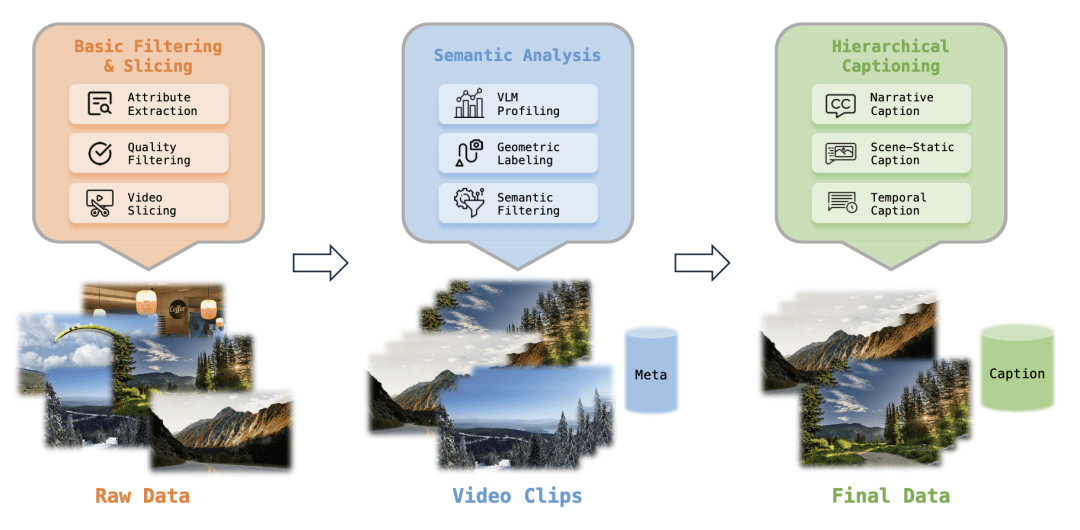
从原始数据,到视频片段,再到最终数据和叙事结构。
模型会先在 5 秒视频上建立基本视频先验,再逐步扩展到 60 秒甚至更长序列,让它在高噪声阶段更多关注全局结构,从而减少长时漂移。
先学画面,再学世界,分阶段演化,把一个视频生成模型,一步步驯化成了世界模拟器,感觉还是很有创意的。
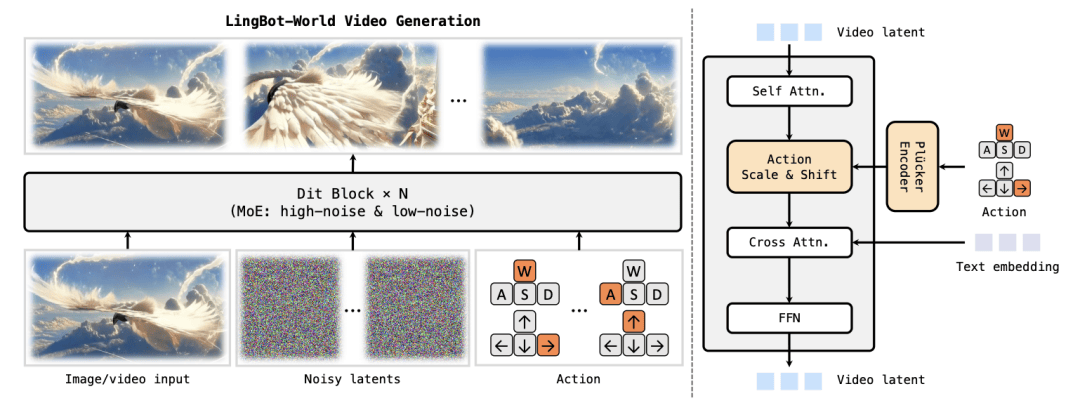
同时,LingBot-World采用了 MoE(Mixture of Experts)结构,把扩散过程拆成高噪声专家和低噪声专家:
前者负责世界整体布局,后者负责细节打磨。
既保持了高分辨率视频能力,又让长程结构更稳定。
看这个结构设计,灵波团队没有说是全盘推倒重来,是在现有视频大模型技术栈上,做了有针对性的世界化改造。
看实际效果,各种细节也可圈可点。
03. 真正可玩:实时交互 + 文本触发世界事件
如果只有长视频,没有实时性,它仍然只是离线渲染器。
LingBot-World另一个跨越式进展是:在约 16 FPS 吞吐下,把端到端交互延迟压到 1 秒以内。
也就是说,用户按下键盘,画面几乎立刻响应,已经接近可玩体验的门槛。
技术上,他们做了两件关键的事:
一是把双向扩散模型蒸馏成因果自回归结构,用 block causal attention 保留局部双向信息,同时满足全局时间因果;
二是通过 few-step distillation,把原本多步采样压缩成少步推理,才能实现准实时生成。
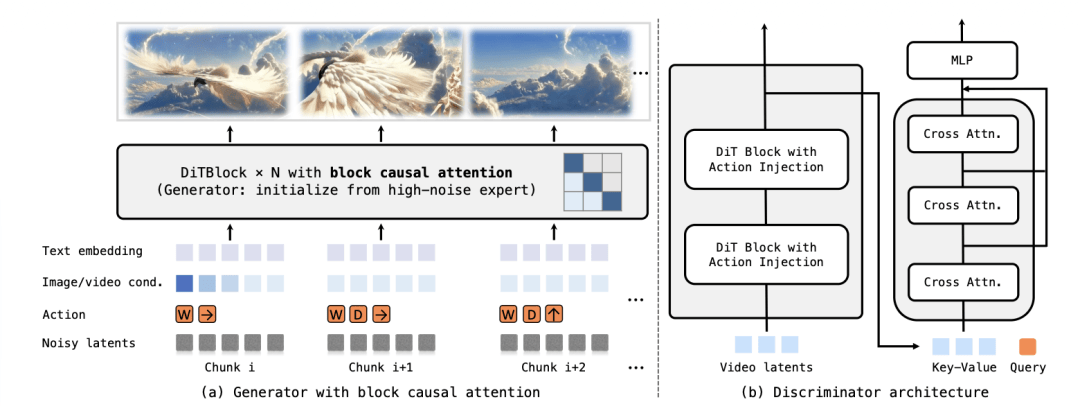
这个阶段的训练,本质是在把“画质优先的老师模型”压缩成“速度优先但逻辑仍在的学生模型”。
更有意思的是文本触发世界事件能力。
用户可以输入“下雪”“夜晚”“像素风”“烟花”等提示,世界会在保持几何结构一致的前提下发生风格或物理状态变化。
上一代世界模型,更多是简单的风格迁移,但是灵波这次,是在一个持续世界状态上施加条件干预。
从应用角度看,这就是未来数字孪生和训练环境构造的核心能力:人可以系统性地改变环境变量,不用重新生成一段无关视频。
终于开始有了可以实时编辑、互动、修改变量的能力。
04. 开源的真正重量:不是模型,而是生态位
还有几个让我印象很深的亮点:
首先是动态离屏记忆,使模型能维持对视野外物体的持久性记忆,确保其在未被观察时仍能自然演进;
其次是探索生成边界,通过极高的时空相干性,支持生成超长且画质稳定的高保真环境;
最后是具身物理约束,模型能够遵循真实的碰撞动力学和空间逻辑,防止物体穿模或忽略物理屏障,从而生成符合物理规律的真实画面。

基于这些持续涌现,不断演化的特质,一个世界模型生态的雏形已经出现。
之前提到的游戏渲染、3D场景,还只是虚拟生态的延伸;而灵波代表的世界模型的触角,已经真实触达了物理现实。
比如说,现实世界里,机器人训练最大的瓶颈是:长程复杂任务数据极度稀缺。
真实机器人跑一次实验成本高、周期长、风险大。
LingBot-World 就提供了一种折中方案:在一个高保真、长时一致、可交互的数字世界里,先进行大规模试错。
它能支持不同光照、摆放变化、风格变化,天然具备 domain randomization 的效果,这对提升现实泛化能力至关重要。

同时,论文还展示了从生成视频中进行 3D 重建的能力,点云结构跨帧一致,说明模型内部已经隐式维持了几何一致性。
这意味着世界模型未来可能成为3D 数据生成的源头工厂,反向为具身感知模型提供训练材料。
从更长远看,我觉得这类模型是在搭建一个认知传感器:
智能体可以在这里形成对物理世界的长期预测能力,已经不需要每一步都依赖真实sensor。
05. 世界模型,开始有“世界味”了
现在世界范围内,最强的世界模型几乎都闭源,导致研究者们,很难真正复现可交互的模型的能力。
LingBot-World是第一次,把权重、推理代码公开。
这也是在向社区释放一个信号:世界模型不该只存在于少数巨头实验室,可以真正走进更多行业。
仔细研究下来,我只觉得,这一步对生态的意义,可能比模型本身更大。
因为一旦开源社区开始围绕世界模型做数据构建、控制接口、物理增强、记忆模块扩展,就会形成一整条新的技术栈,终于不再是只停留在视频生成赛道了。
当然,它还远未完美。
论文里也坦诚:记忆仍是涌现能力、不稳定;动作空间有限;细粒度物体交互困难;推理成本高;多智能体尚未支持。
但这些问题的存在,本身说明它已经从演示级模型进入了可工程迭代的阶段。
最后我想说,LingBot-World 代表的不仅是一次模型刷新,更是一次方向确认:
AI 正在从生成内容,走向生成可被持续体验、被智能体利用、被人类实时介入的世界。
当视频长度变成分钟级,当镜头离开再回来物体仍在,当你按下键盘世界就响应,当一句话可以改变天气和风格——这已经不是生成或者消费AI作品,是真的在进入 AI 构建的环境。
对灵波而言,世界模型还有个很重要的意义:为具身智能搭建一个可以反复试错、低成本进化的数字现实。
在真实物理世界中,机器人每一次训练都昂贵且缓慢,而世界模型让智能体能够在虚拟环境里提前经历长时序任务、理解“动作如何改变环境”的因果关系,并逐步形成稳定的规划与决策能力。
当这些能力在数字世界中被充分打磨后,再迁移到现实世界,具身智能的落地速度和泛化能力才真正具备规模化可能。
在这条路上,LingBot-World 让开源阵营第一次站到了第一梯队门口。
接下来,真正的变化,可能不在论文,就在接下来长出来的具身智能新系统、新智能体和新应用里。
2026年,世界模型这个核心命题,蚂蚁灵波已经打响了关键的一枪……
)
)
)

)
)
)
)
)
)

)


)
)